内置变量
无论 Dynamic tracing 或者 Static tracing,它们的目的都是监听特定函数调用事件,这些函数即可以在内核中,也可以在用户态的应用或者 lib 中。获知这些函数调用时的参数、返回值就已经实现了开发者大半目标。除此之外,bpfstrace 还内置了一些变量,用户访获得探测对象自身信息。这些变量在 bpftrace 中直接访问即可。
pid/tidBpftrace 或者说 eBPF 工作在内核,因此这些变量都与内核中进程表示有关。
先说
tid,内核中线程与进程没做作明确区分,它们都是相同的调度对象task_sruct。tid是 thread id 的缩写,由于历史原因,在 task 中的成员是task_sruct.pid。所以对于 Linux 内核,线程 = 轻量级进程。而
pid实际上指的是内核中进程组,由 task 中的task_sruct.tgid成员表示。也就是说,进程 = 线程组。
uid/gid执行函数的用户ID、组ID。
nsecs时间戳,纳秒。
elapsedebpfs 启动后的纳秒数。
numaidNUMA = Non-Uniform Memory Access,与多核 CPU 的内存访问相关。
cpu当前 cpu 编号,从 0 开始。
comm进程名称,通常为进程可执行文件名。
kstack内核栈。
ustack用户栈。
arg0,arg1, ...,argN函数参数。
sarg0,sarg1, ...,sargN.函数参数(栈中)。
retval返回值。
func函数名,可以在可执行文件的符号表中这个函数名。
probe探针的完整名称,也就是 bpftrace 中 形如 'kprobe:do_nanosleep'
curtask当前 task struct。
rand一个无符号 32 位随机数。
cgroup当前进程的 Cgroup,内核资源组,类似 namespace,docker 等虚拟化技术即基于内核提供的这一基础设施。
cpid子进程 pid,bpftrace 允许通过
-c指定一个cmd运行,然后在该进程上安装 probe。$1,$2, ...,$N,$#.bpftrace 程序自身的位置参数
这些内置变量可以在 bpftrace 脚本中直接使用。
变量
bpftrace 不仅能将监测到的函数调用信息 print 出来,更进一步,它提供了存储空间,允许在处理 probe 时保存、累计数据。bpftrace 脚本最终被编译为 Bytecode,由 eBPF VM 执行。
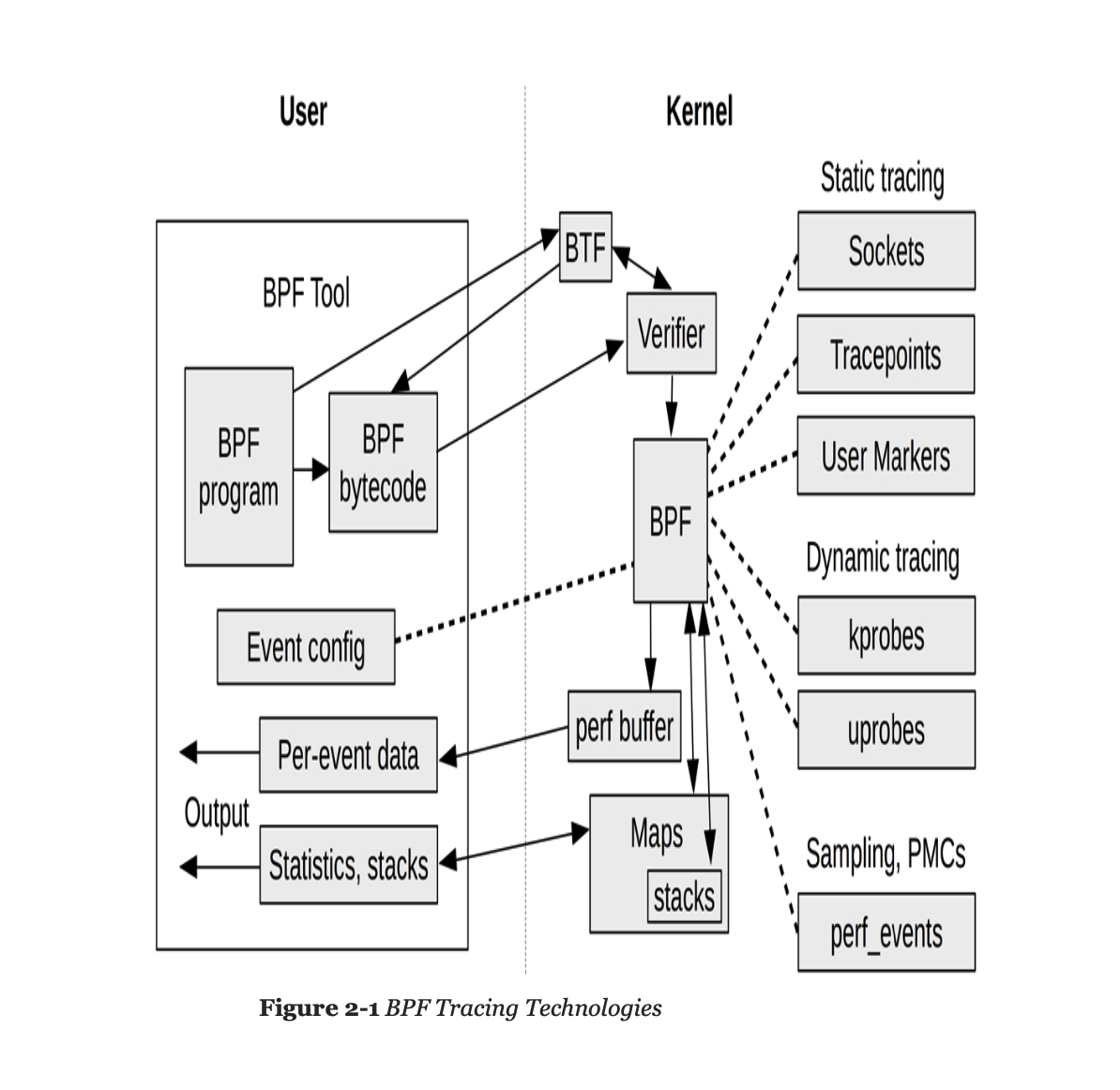
不同于传统的 trace 技术仅提供有限的 ring buffer,eBPF 为 VM 提供了无上限的存储 Maps(图中底部中间)。bpftrace 也可以读写 Maps,在多个 probe actions 和 多次事件中保存数据,直到 bpftrace 程序退出或者主动清除。
全局变量 @name
所谓全局有几个方面的意思:
- 对所有 probe actions 可见;
- bpftrace 生命周期内可见;
bpftrace 支持两种变量形式:
- 简单变量,
@name = value - Map,
@name[key] = value
简单变量就是单纯的变量名和值,很容易理解,你可以在脚本中创建任意数量的简单变量。
Map 非常接近 Python 中的 Dict,或者 C 中的数组,但数组索引可以是数字、字符串等。例如借助内置变量 tid 可以为每个线程记录独立的数值。
# example.bt
kprobe:do_nanosleep {
/*以线程 tid 作为 key,不同线程的 value 不同*/
@start[tid] = nsecs;
}
kretprobe:do_nanosleep /@start[tid] != 0/ {
printf("slept for %d ms\n", (nsecs - @start[tid]) / 1000000);
delete(@start[tid]);
}
# bpftrace example.bt
Attaching 2 probes...
slept for 1000 ms
slept for 1000 ms
slept for 1000 ms
slept for 1009 ms
slept for 2002 ms
临时变量
$name, 只在当前 action 中有效,超出 action 的 {}不具备记忆能力。
