由于 unicode 在 Python 中使用频率极高,Python 3 针对 unicode 提供了大量接口和优化,其中最基本的是 PyUnicode_New 和 _PyUnicode_New 函数,分别提供了两种不同的存储方式。
PyUnicode_New
删除掉一些与主要逻辑无关的代码,逻辑并不复杂。
// Object/unicodeobject.c:1387
PyObject *
PyUnicode_New(Py_ssize_t size, Py_UCS4 maxchar)
{
PyObject *obj;
PyCompactUnicodeObject *unicode;
void *data; //数据区指针
enum PyUnicode_Kind kind;
int is_sharing, is_ascii; // is_sharing 决定了 wstr 指针是否共享数据区,
// 这里假定 sizeof(w_char_t) 为 4。
Py_ssize_t char_size;
Py_ssize_t struct_size;
is_ascii = 0;
is_sharing = 0;
// 省略一些代码,根据 maxchar 决定使用那种结构,确定结构体尺寸 struct_size
// 从内存池分配内存
obj = (PyObject *) PyObject_MALLOC(struct_size + (size + 1) * char_size);
// 设置对象类型为 unicode type
_PyObject_Init(obj, &PyUnicode_Type);
// 注意,这里计算 data 指针的位置
unicode = (PyCompactUnicodeObject *)obj;
if (is_ascii)
data = ((PyASCIIObject*)obj) + 1;
else
data = unicode + 1;
// 省略一些代码,设置 unicode object 的长度、state 属性
// 由于 Python 使用与 C 同样的策略,在字符串结尾需要设置 '\0' 作为 terminal code
// 根据不同类型设置 data 结尾处的值。
if (is_ascii) {
((char*)data)[size] = 0;
_PyUnicode_WSTR(unicode) = NULL;
}
else if (kind == PyUnicode_1BYTE_KIND) {
// ...
}
else {
// 省略,根据不同的字符宽度计算 data 结尾的位置,并设置为 0
// 如果字符宽度与 w_char_t 相同,那么设置 unicode object 的 wchar 指针指向数据区 data。
if (is_sharing) {
_PyUnicode_WSTR_LENGTH(unicode) = size;
_PyUnicode_WSTR(unicode) = (wchar_t *)data;
}
// ...
}
return obj;
}
通过 PyUnicode_New 创建的 unicode 对象是一个连续对象,即对象的头部与数据是一体的,一个 ASCII 字符串对象看起来是这样:
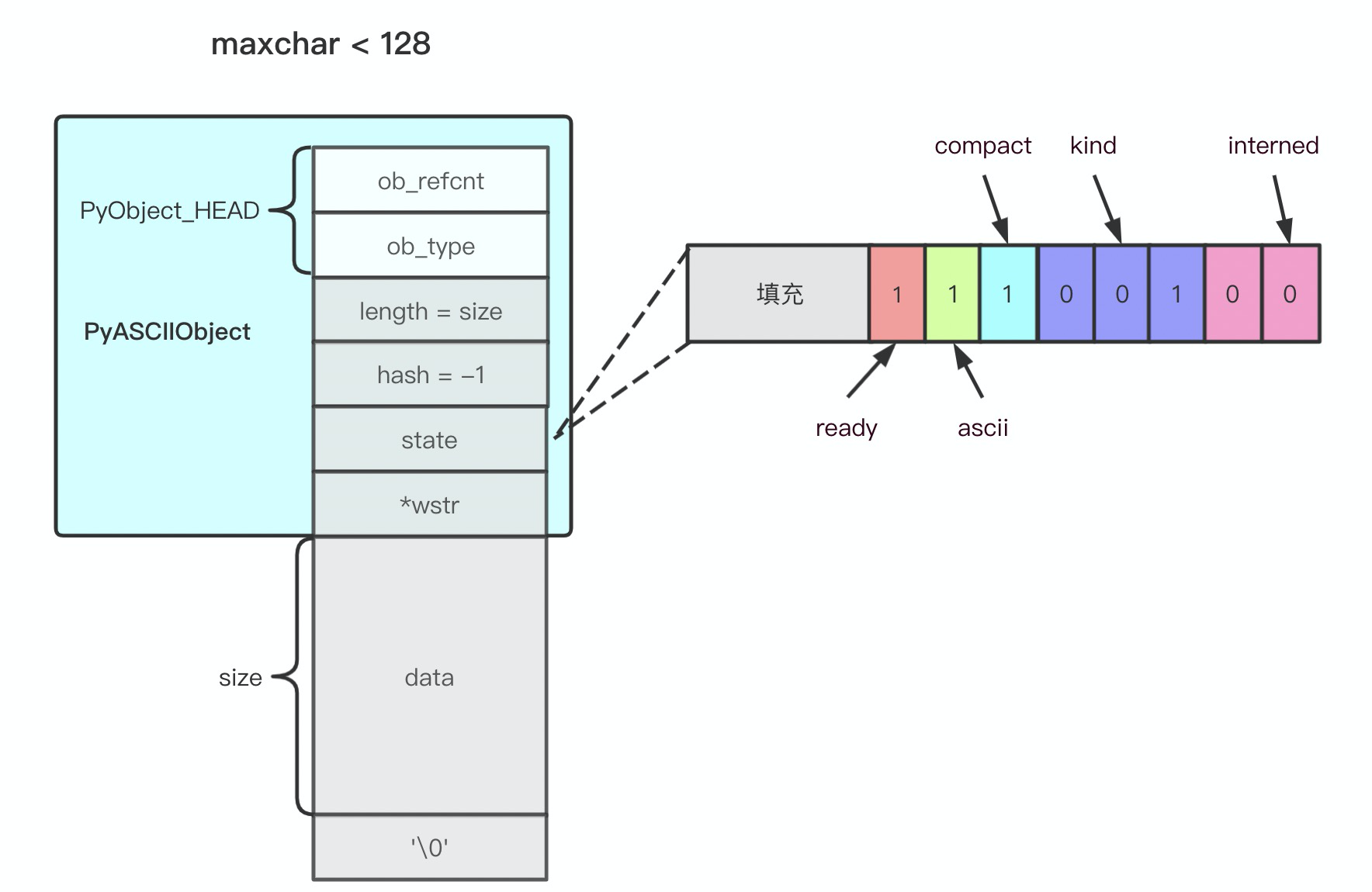
是一个 ASCIIObject 为头部的 C 风格字符串对象。 4 字节宽的字符串对象看起来是这样:
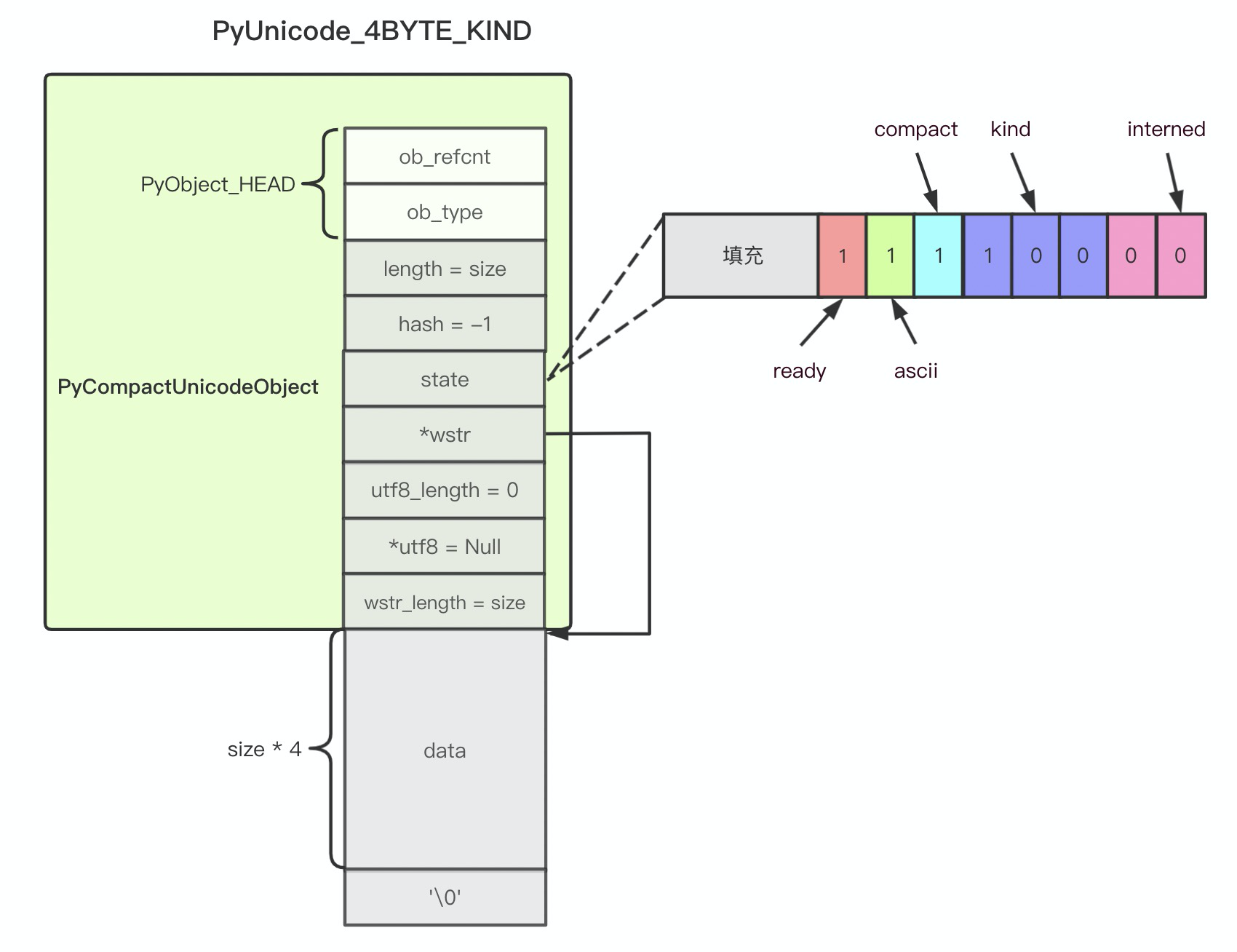
则是一个 PyCompactUnicodeObject 为头部的 C 风格字符串对象。当 w_char_t 大小与 unicode 字符宽度一致事,wstr 指针指向自身的数据段。
_PyUnicode_New
这个函数则更加底层,不是开放的 C API。
static PyUnicodeObject *
_PyUnicode_New(Py_ssize_t length)
{
PyUnicodeObject *unicode;
size_t new_size;
// 创建一个 PyUnicodeObject 类型的 PyObject 对象
unicode = PyObject_New(PyUnicodeObject, &PyUnicode_Type);
// 计算数据区域大小
new_size = sizeof(Py_UNICODE) * ((size_t)length + 1);
// 设置 unicode 对象的一些属性,除了 hash 设置为 -1, length设置为 length,其他设置为 0
// 从内存池分配真正的数据区
_PyUnicode_WSTR(unicode) = (Py_UNICODE*) PyObject_MALLOC(new_size);
// 设置数据区域结尾和开头的 ‘\0’,逻辑上与 memset 数据区为 0 一样
_PyUnicode_WSTR(unicode)[0] = 0;
_PyUnicode_WSTR(unicode)[length] = 0;
return unicode;
}
通过这个函数创建 unicode 实例,只需要一个长度参数,非常简单。它创建的对象结构与前一种函数也不同,数据与类型对象通过指针关联起来。看起来像这样:
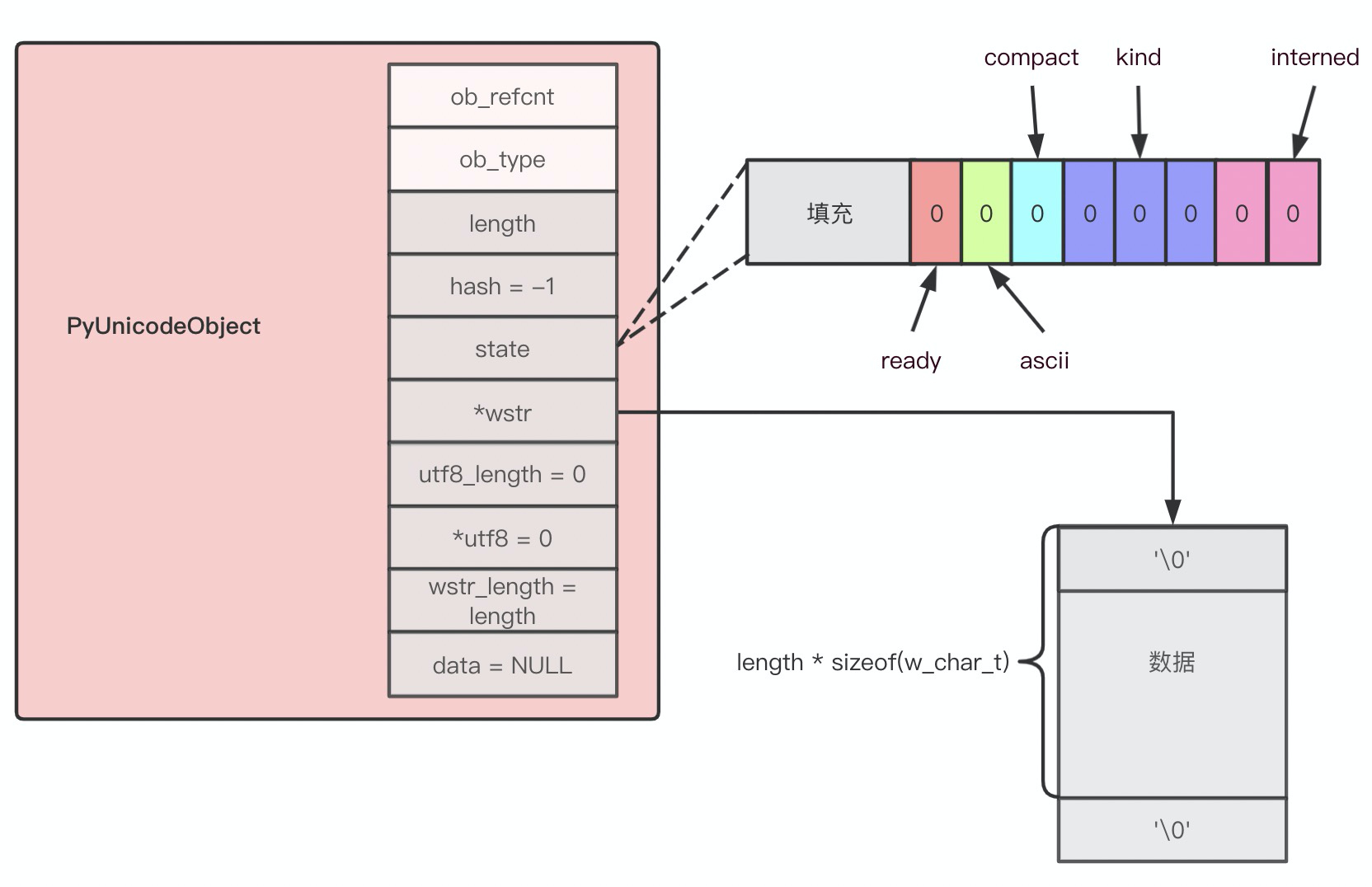
这是一个非常原始的数据结构,默认会使用 w_char_t 保存数据。使用该函数创建对象后还需要进一步处理才能使用。
