String Object 采用了多种结构,以适应不同应用场景的内存使用效率,String Object 最要有以下几类:
- latin-1 字符串;
- UCS2 类型即 2 字节 16 位字符串;
- UCS4 类型即 4 字节 32 位字符串;
在创建 String Object 的时候,会要求提供欲创建字符串的最大码点,进一步确定存储最大码点所需要的空间是 1、2、4 字节之一,然后将所有码点的宽度对齐到最大码点宽度。因此即使是单字节字符,比如 ‘A’,在不同字符串中,可能存储在不同大小的空间中。(中文是双字节码点)
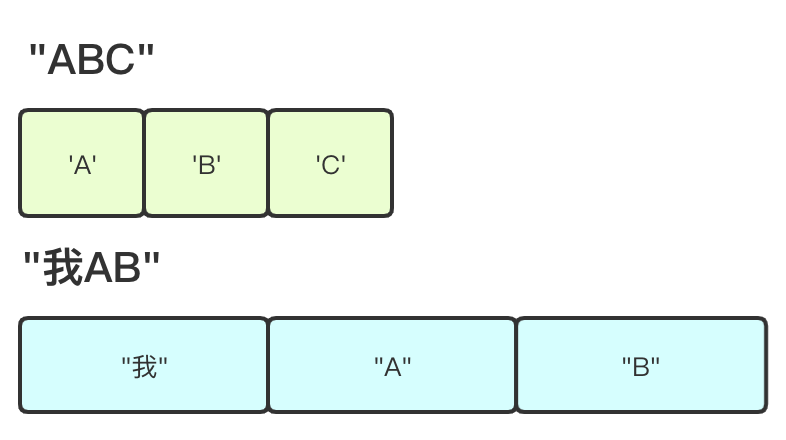
一个字符串字符的存储宽度与字符串中最宽码点有关。
为什么?
Unicode 最受欢迎的编码格式 utf-8 并没有直接被应用到 Python 的内部字符串表示中,回顾前面提到的 Unicode 表示,utf-8 格式是一个变长编码,在存储时有优势,但是在字符串处理中就不是很方便,比如它无法很好的支持字符串索引,变长数据无法直接根据偏移获取字符。而转换为相同宽度的编码格式,就可以很方便的利用索引操作字符串,比如上面的字符串可以通过下面两种方式快速索引到 'A':
// "ABC" 字符串
((Py_UCS1 *) data)[0]
// "我AB"
((Py_UCS2 *) data)[1]
因此 Python 使用多种宽度的字符串表示,是为了提高内存利用效率;同一字符串内将所有码点扩展到相同宽度则是为了方便操作。
