到目前为止,有关内存池的操作已经大体清楚了:
- 内存池 pool 的大小正好是操作系统内存页的尺寸:4K;
- 内存池的结构体在 pool 内存的头部,与其管理的内存连续;
- 内存池被分割为相同大小的 block,block 大小为 8 的整数倍;
- 内存池的 block 被用过一次归还 pool,会被插入 freeblocks 链表的头部,这是一个单向链表;
- 当 freeblocks 链表用完后,会从未使用的区域分配 block;
关于 pool 实际上还有两个重要的操作,这里只提一下,在后面研究 arena 的时候会详细介绍。pool 有三种状态:
- 所有 block 都是空闲的;
- 部分 block 占用,部分空闲;
- 所有 block 都被占用;
其中空闲的 pool 链表由 arena 的 freepools 链接,部分 block 可用的 pool 则由全局数组 usedpools 链接。
其中 usedpools 的结构看起来如此:
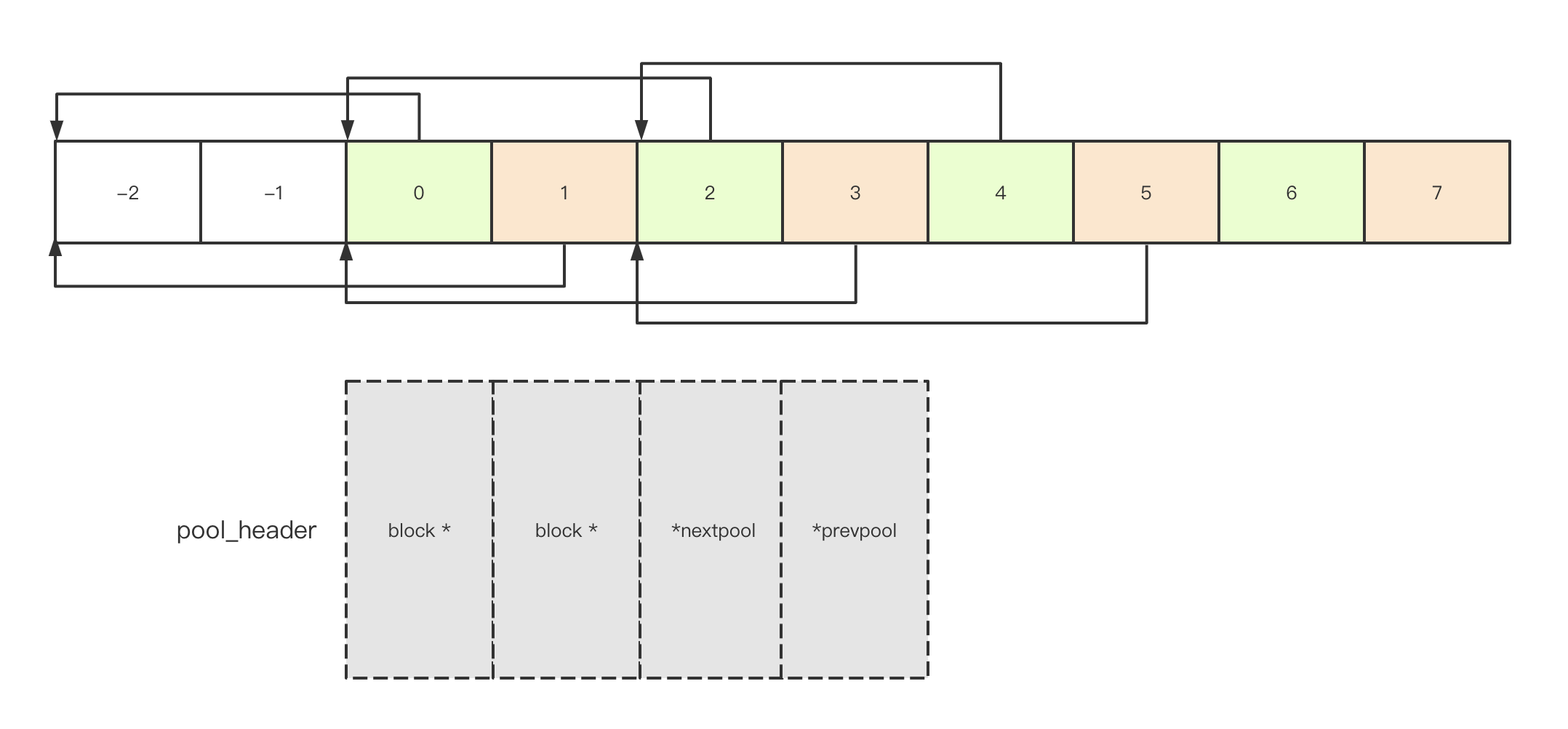
Python 利用这样的结构,实现
usedpool[i+i]->next_pool
访问 block size 为指定大小的 pool,初看之下实现特别费解,尤其是代码里的 i+i 不明所以,如果将 pool_header 的结构如图按字节与 usedpools 数组对照,就能理解,0、2、4 这样位置的指针是对应 size_index 的 next_pool 指针,1、3、5 这样位置的指针是对应 size_index 的 prev_pool 指针。代码中这种结构,可以使数组在初始化的时候,就让:
- usedpool[i+i]->next_pool == usedpool[i+i]
- usedpool[i+i]->prev_pool == usedpool[i+i+1]
如果仅从实现效果上说,可以有以下等效实现:
#define NEXT_POOL_FIRST_NODE(size_index) (usedpool[2*(size_index)])
#define PREV_POOL_FIRST_NODE(size_index) (usedpool[2*(size_index) + 1])
// 获得链表第 1 个节点指针
NEXT_POOL_FIRST_NODE(size_index)
// 获得链表第 2 个节点指针
NEXT_POOL_FIRST_NODE(size_index)->next_pool
或者:
typedef struct {
struct pool_header *nextpool;
struct pool_header *prevpool;
} usedpools_el;
static usedpools_el usedpools[((NB_SMALL_SIZE_CLASSES + 7) / 8) * 8] = {NULL};
// 访问链表第 1 个节点指针
usedpools[size_index].next_pool;
// 访问链表第 2 个节点指针
usedpools[size_index].next_pool->next_pool;
显然后面两种常规实现,相比 Python 中的实现就不那么优雅了,它们无法将第一个元素的访问与之后元素的访问达成统一。usedpools 数组的这种实现,按 tricks 论也是不为过的。
