这一段在 GC 与内存管理中消耗了一些时间,今天终于可以回归求知旧路,继续探究下一个重要的内置类型: Dict,字典。与 List 类似,它也是一个容器,基于之前对 GC 的了解,我们可以确定字典的内存是由 GC 管理的。在 Python 内部广泛使用了字典对象,比如面向对象计数、变量管理等等,因此字典的实现在很多层面影响这 Python 自身。
首先了解 Python 字典的作用,在其他编程语言中,通过 Map、table 等方式实现与 Python 字典类似的功能。Dict 的命名比较形象的说明了它是如何工作的:
- 通过一个唯一索引,比如拼音;
- 找到一个生字。
一图胜过千言,table、Dict、Map 解决的问题本质是:集合映射。
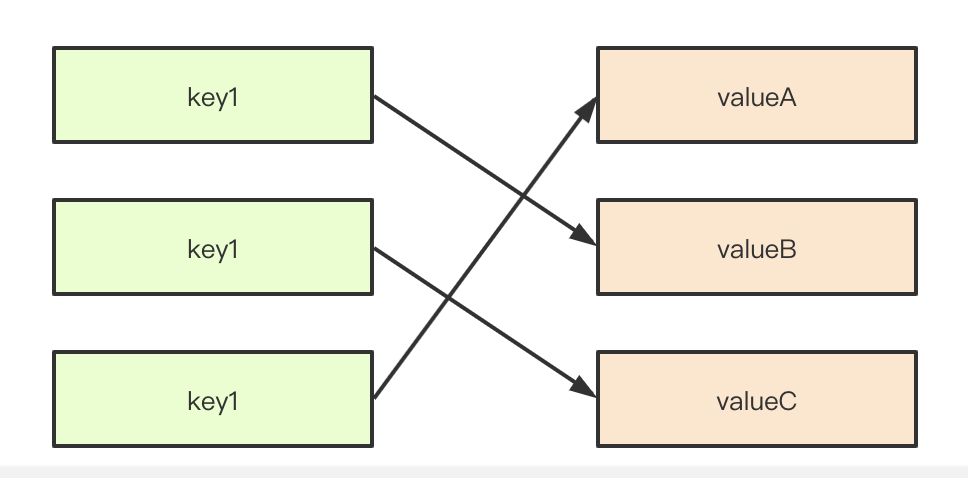
其实每个人在小学阶段都做过类似的问题,将两组数据关联起来。其中左侧成为 key 键值,右侧为 value 值,其中所有 key 必须不同,value 可以重复。也就是说下面一种情况也是可能的:
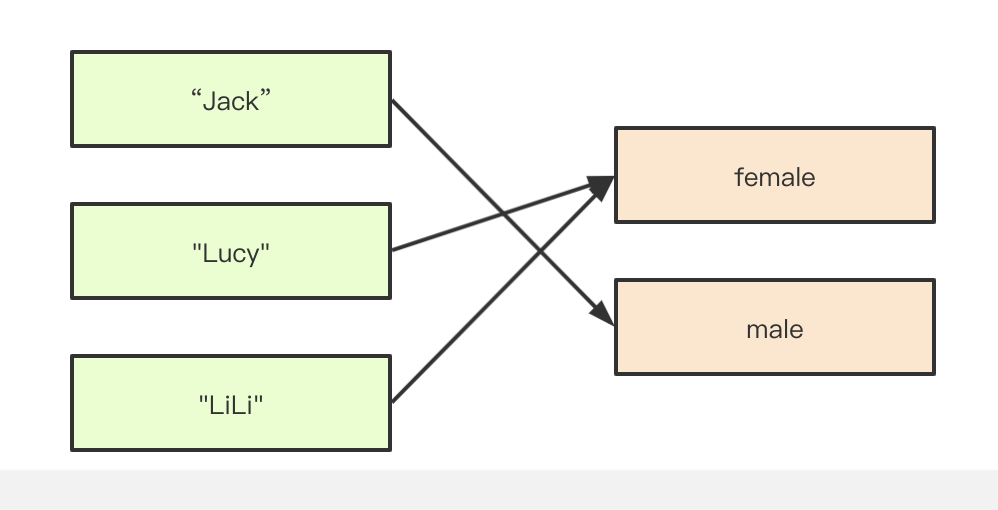
- 每个人都有唯一的性别;
- 但不同的人可以有相同的性别。
key 的检索
假设我们想直到 “LiLi” 的性别,那么步骤可以简化为 2 步:
- 在 key 中找到 "LiLi";
- 从 “LiLi” 找到它对应的 value。
其中第二步是很直白的,因为 “LiLi” 和它的性别是直接通过引用关联的,只要找到 “LiLi” 就找到它的性别了。如果只有简单的几个 key,那么你可以轻松的给出 “LiLi” 的位置,如果有 1 万个 key 呢? 10 万个呢? 这就需要一些更具技巧的做法了。
搜索算法有很多,从最简单的遍历到基于树,还有就是 Python 采用的基于 Hash 的算法,其他算法在此不再展开。Hash 绝大多数人都听过。基于 Hash 的搜索算法的基本思路是将随机搜索转换为数组的索引问题。假设我们有一个公示 h(x),有:
- h('Jack') = 0;
- h('Lucy') = 1;
- h('LiLi') = 2;
并且我们用 0 表示 female, 1 表示 male,可以注意到 h(x) 刚好将几个姓名转换为 不同 的整数,这些刚好可以关联到数组的索引。
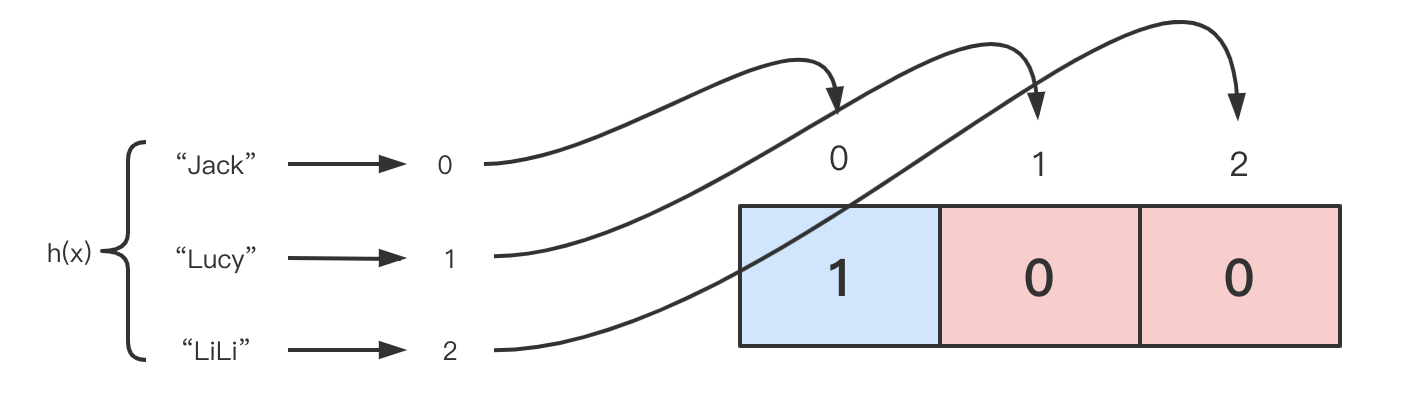
这样我们就将 key 的搜索问题,转换为数组的索引问题。这种情况下查找指定 key 的复杂度是多少呢?达到了惊人的 O(1),这就是 Python 字典的最佳情况。
实际上这里我们忽略了一个关键的问题,这个 h(x) 函数是什么,有这样的智能将所有输入转换到不重复的整数,很显然这是很罕见的。事实上也确实如此,Hash 函数很有可能对将不同的 key 转换为相同的整数,这就很难决定数组中这个整数索引的 “宝座” 到底该给谁了,这种现象就是哈希函数的碰撞问题。后面深入了解字典的实现,在看如何处理碰撞问题。
具备良好碰撞性能的哈希函数需要精心构造,但哈希函数并不一定很复杂,下面实现一个非常简单的哈希函数,将任意整数映射到 10 以内的整数:
h(x) = x % 10
只是一个简单的求余数函数,对 10 以内的整数具备良好的碰撞性能,但对大于 9 的整数就会出现碰撞。哈希的逻辑并不复杂,但构造性能较好的哈希函数会困难一些。
