目前已经对 Dict 的增查改删有了比较清晰的认识,对 Dict 的增删环节一直有一个细节没有澄清:
dk_entries 是如何伸缩的?
对 Dict 的内存伸缩过程理解了,才能真正搞清 dict.keys() 的顺序这样的问题。
增删过程
前面我们只简单的说明从空 Dict 插入和对已有 Dict 的 key 删除,实际上 Dict 的增删是由用户随机决定的,在生产中更常见的情形是,删除了一些元素,又新增了一些元素,又删除另外一些。让我们从最简单的情况开始。
对于一个新创建的 Dict 对象 a,其拥有长度为 8 的哈希表 dk_indices 和 长度为 5 的 K-V 容器 dk_entries。Dict 对象有一些内置变量:
- dict->ma_used,dict 中的元素数量,与 dict.len() 实际返回的就是这个值;
- dict->ma_keys->dk_usable,dict 中可用 dk_entries 数量;
- dict->ma_keys->dk_nentries,dict 中已用 dk_entries 数量;
其中 dict->ma_keys->dk_usable 永远自减,dict->ma_keys->dk_nentries 永远自增,它俩的和总是 dk_entries 的长度。
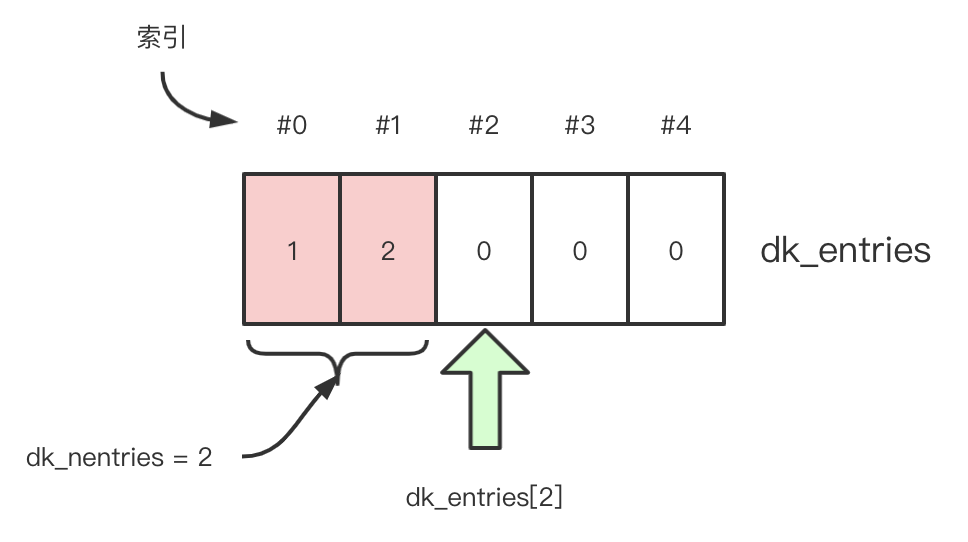
新插入的 K-V 总是被保存在 dict->ma_keys->dk_entries[dict->ma_keys->dk_nentries],由于 C 语言数组是从 0 开始索引的,比如 dk_nentries 是 2,目前数组中已有 2 个 entry,那么 dict->ma_keys->dk_entries[dict->ma_keys->dk_nentries] 实际上表示的是 dk_entries 的第三个位置,图中绿色箭头指向的位置,刚好是第一个可用位置。当某个 K-V 被删除时 dk_nentries 不会减少,这个绿色箭头也不会回退,新插入的 K-V 也不能复用新腾出来的 entries,新 K-V 总是被追加到 dk_entries 的尾部!
为了方便,我们采用整数作为 key,采用更简单的探测链算法 i = j + 1, 即所有碰撞的 Key 依次插入哈希表,以便它们在 dk_indices 上连续的放置,更容易理解。
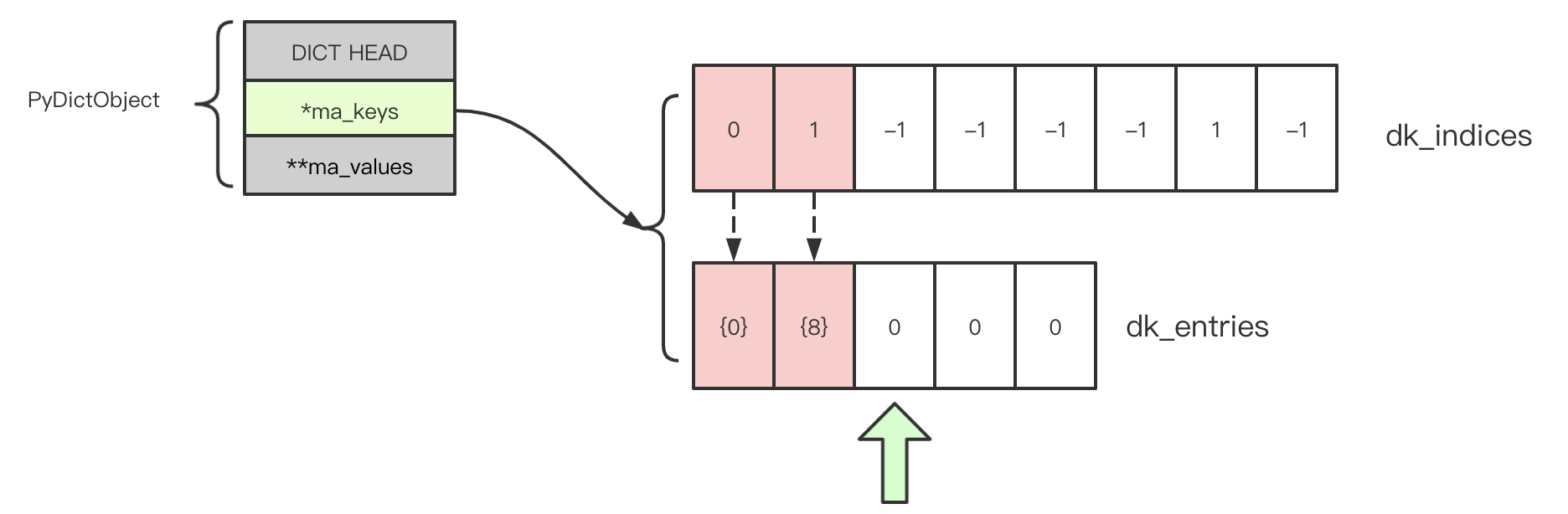
首先插入 {0: "value"},0 mod 8 == 0,dk_indices 中第一个位置可用,此时 dk_entries 中第一个空闲位置用来存储 0 <-> "value",并将索引 0 写入 dk_indices[0];
接着我们再插入 {8:"value"},8 mod 8 == 0,检查 dk_indices[0],发现已经被占用,尝试下一个探测点 i = 0 + 1,发现可用,将 8 <-> "value" 保存在 dk_entries[1],并将索引 1 插入刚才找到的可用探测点 dk_indices[1]。
图中虚线表示哈希表与对应 dk_entries 之间的逻辑关联。注意,图中绿色箭头表示下一个插入的 K-V 会被保存在这里。我已经将所有占用的位置标记为红色。
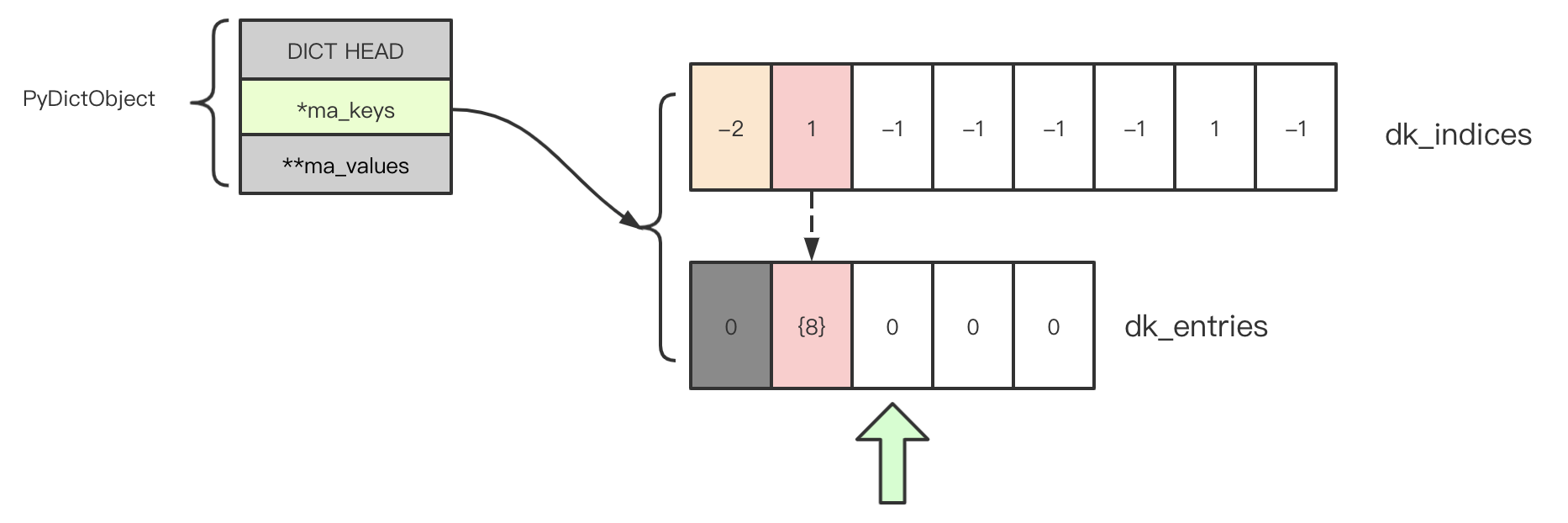
当删除 a[0],显然会将 dk_indices[0] 设置为 DKIX_DUMMY,也就是 -2(图中标记为橘色,因为它稍后可能被再次利用),并且将对应的 dk_entries[0].key = NULL, dk_entries[0].value = NULL(图中以灰色的 0 表示,因为它不会被再次使用)。
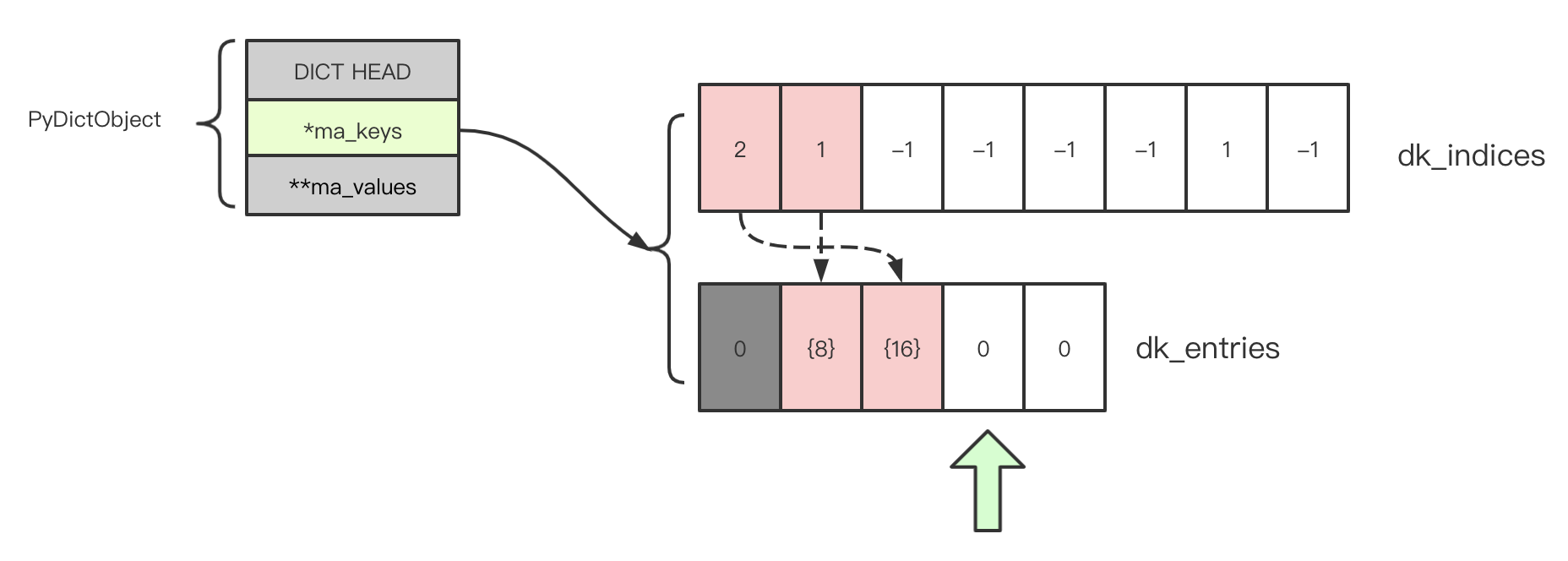
当再次插入一个 K-V,我们选择一个特例,再次插入一个冲突的 {16 : "Value"}。16 mod 8 == 0,dk_indices[0] 为 DKIX_DUMMY 会被复用,但 dk_entries 只会使用绿色箭头指向的位置,即使 dk_entries[0] 也是空的。因此 16 <-> "Value" 会被保存在 dk_entries[2],dk_indices[0] 也从 DKIX_DUMMY 设置为 2 重新成为有效状态。
注意到 dk_indices[0] 再次变为有效值 2,绿色箭头自增 1,下一个插入的 K-V 会写入这里。
内存伸缩
dk_entries 貌似只能不断变的更长,初始创建的长度为 8 的数组怎么能够呢?Python 会在合适的时候重新整理内存,比如检查 dk_entries 剩余可用空间,或者 Dict 从 splited 模式转换为 combined 模式,相关函数是 dictresize。其基本思路是:
- 创建一个新的 PyDictKeysObject,其 dk_indices 长度为 dict->ma_used 对 2 向上取整,最小为 8, dk_entries 大约为 dk_indices 长度的 2/3;
- 遍历原 dk_entries,将其中有效值复制到新的 dk_entries 中;
- 更新新建的 PyDictKeysObject 的哈希表 dk_indices。
在复制过程中,抛弃了废弃的 dk_entries 和 设置为 DKIX_DUMMY 的 dk_indices,所以 dictresize 不一定会扩大内存,也可能清理掉废弃的部分,达到收缩的效果。
假设运行一段时间后,a 看起来这样:
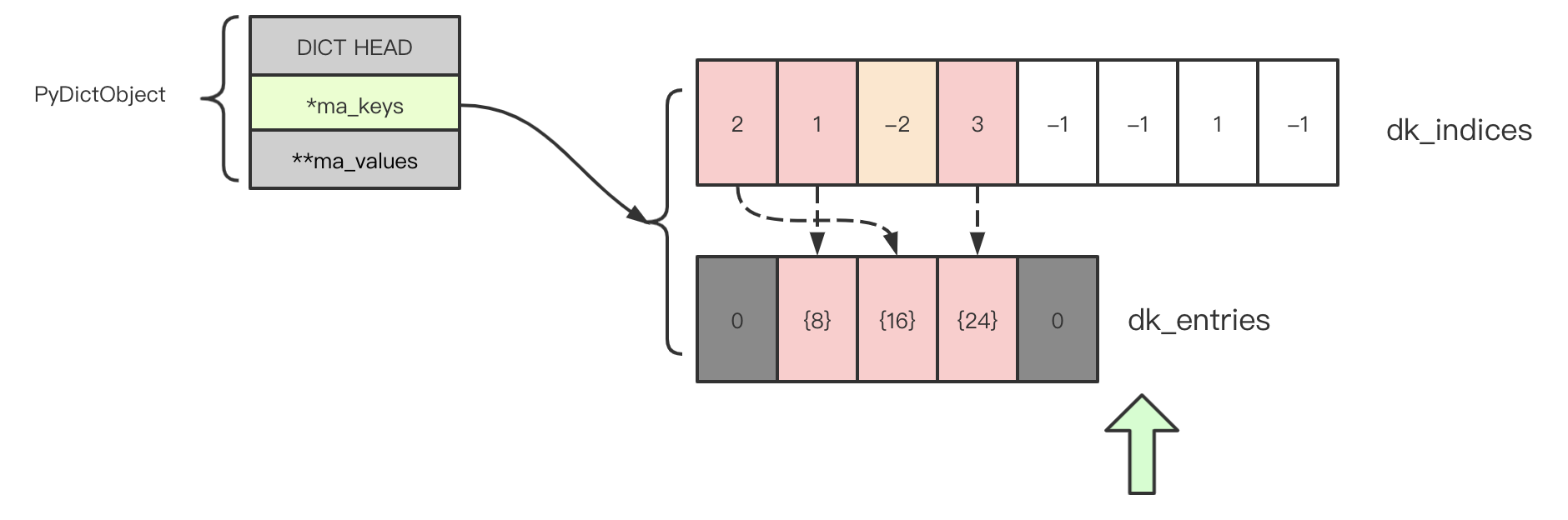
dk_indices 中有 1 个 DKIX_DUMMY, dk_entries 中有 2 个废弃 entry。当我们调用 dictresize 伸缩 a 的尺寸(为了简化,不扩大内存,只剔除无效值),结果是这样:
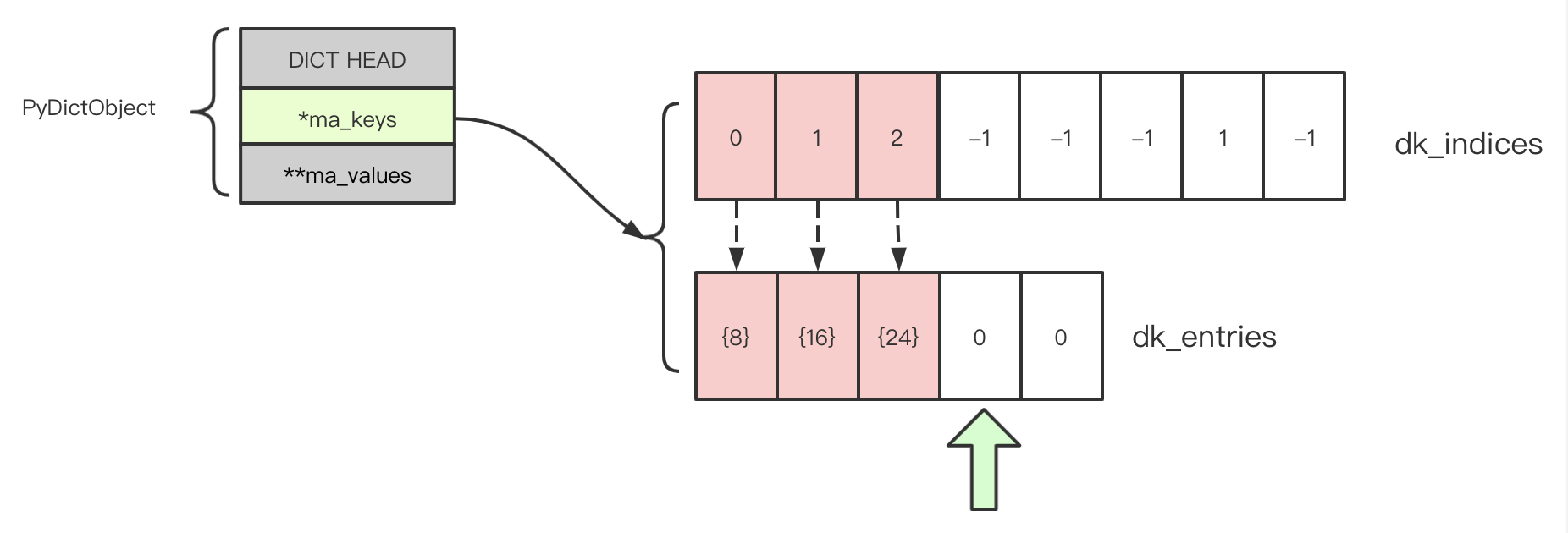
需要注意的是,实际情况下哈希表 dk_indices 的顺序可能更加分散,但可以确定的是 dk_entries 与实际情况差不多。
总结
由于内存伸缩中的重建中,保留了 dk_entries 中有效值的先后顺序,而访问 dict.keys() 视图实质上也是访问 dk_entries 中的有效值,所以 Python 3.8 的 dict.keys() 之类函数的返回值与插入顺序一致。
Dict 的 dk_entries 随着字典的插入而不断膨胀,在适当的时候 Python 会整理 Dict,剔除那些无效值,扩展或者收缩内存到合理的尺寸。
