TupleObject 是 Python 中另外一种常用对象,尤其是赋予了函数返回多个对象的能力。Tuple 可以看作是 “只读” 版本的 List,在最底层的 Object * 数组操作上二者有异曲同工之妙,加上 Tuple 的只读特性,Tuple 比 List 更加简单。今天仅通过一文快速掌握 Tuple 的大体工作原理。
TupleObject 的结构
按照惯例,第一步当然还是先认识 Tuple 到底长什么样子,Tuple 的结构非常简单且紧凑:
// Objects/tupleobject.h:9
typedef struct {
PyObject_VAR_HEAD
PyObject *ob_item[1];
} PyTupleObject;
还是熟悉的配方,熟悉的味道,PyObject_VAR_HEAD 打头,后面紧跟着一个 PyObject 数组。需要注意的是,虽然在结构体的定义中只有一个 ob_item,但实际在其后连续内存中,可能有更多 Object 。从 Tuple 的定义来看,它也是一个容器:
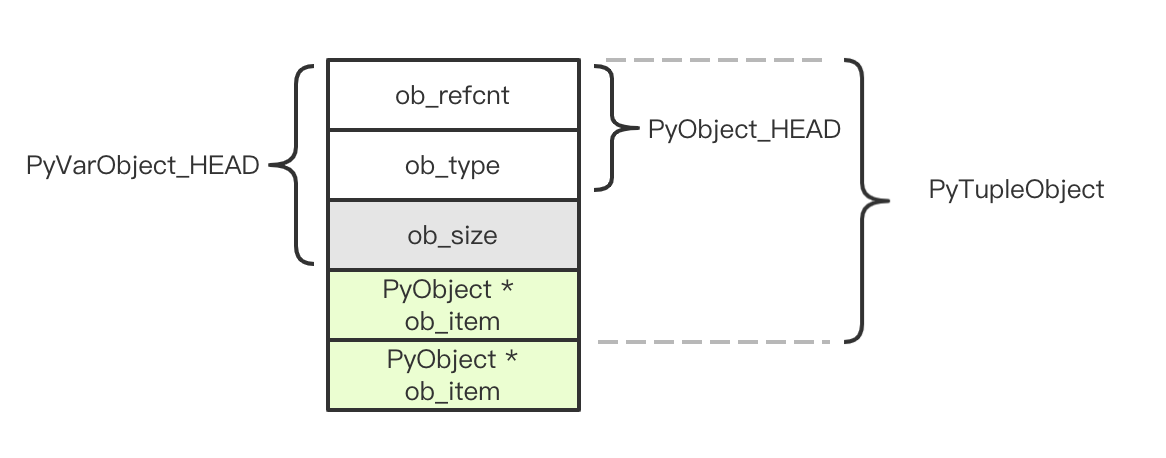
图中 PyTupleObject 所指示的区域是严格的 PyTupleObject 定义,但实际上 C 语言的数组没有边界检查,无限延长 ob_item 也是没问题的,图中所示的是一个包含 2 个 Object 的 TupleObject。这是一种 Python 中非常常用的技巧。
对比 ListObject 的结构,Tuple 的类型信息与数据区是连续的,套用 DictObject 中的说法,它们是 combined 模式。
Tuple 的创建
Python 中所有的容器类型,都需要在由 GC 管理,其他普通类型只需借助引用计数即可完成内存管理工作。Tuple 的数据区保存的是通用的 PyObject ,作为一个容器,它的创建当然也离不开 GC_New_ 之类的函数。
// Objects/tupelobject.c:80
PyObject *
PyTuple_New(Py_ssize_t size){
// ··· ···
// Objects/tupelobject.c:118
op = PyObject_GC_NewVar(PyTupleObject, &PyTuple_Type, size);
// ··· ···
}
// Include/objimpl.h:257
#define PyObject_GC_NewVar(type, typeobj, n) \
( (type *) _PyObject_GC_NewVar((typeobj), (n)) )
// Modules/gcmodule.c:2005
PyVarObject *
_PyObject_GC_NewVar(PyTypeObject *tp, Py_ssize_t nitems)
{
size_t size;
PyVarObject *op;
// ··· ···
// size = basic_size + nitems * item_size
size = _PyObject_VAR_SIZE(tp, nitems);
// GC Malloc here
op = (PyVarObject *) _PyObject_GC_Malloc(size);
// ··· ···
}
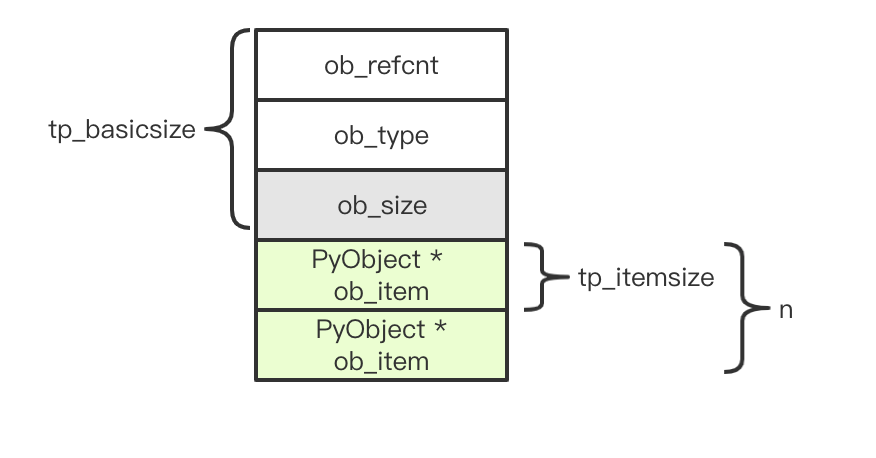
经过层层调用,终于还是经过 _PyObject_GC_Malloc 将内存分配在 GC 的控制之下,实际分配的内存大小是:
size = basic_size + nitems * item_size
即类型的基本尺寸 + 容纳数据尺寸 * 数量。其中 basic_size 和 item_size 在这里定义:
// Objects/tupleobject.c:829
PyTypeObject PyTuple_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"tuple",
sizeof(PyTupleObject) - sizeof(PyObject *), // tp_basicsize
sizeof(PyObject *), // tp_itemsize
// ··· ···
};
其实就是图中所示的大小:
Tuple 采用连续存储是因为它是 “只读” 的,一旦创建好就不会再伸缩。实际上 Tuple 被创建以后一段时间内,当一切还在 C 控制之下时,Tuple 的数据可能是 NULL 或者被改变,但是一旦 Tuple 进入 Python 世界它就不可以在改变了。
Tuple 的 “只读” 是如何实现的呢?其实在 C 语言这一层,一切都可以被操作, Tuple 的只读只是在 Python 语言层面才有意义,毕竟 Tuple 被创建出来的时候还是一穷二白,初始化过程中的 set item 必定是存在的,但是我们无法直接通过 Python 代码修改 Tuple items。
对元素的操作
Tuple 被创建并初始化后,Tuple 就可以大致看作是一个普通的 C array 了。对 items 的读写实际上都是对 Tuple.ob_items[] 数组的操作,逻辑并不复杂。元素的长度则更直接,就是 PyTupleObject 的 ob_size 值。
Tuple 的缓存
Python 在性能优化上的努力可以说是不遗余力,几乎所有类型都提供了缓存 freelist,Tuple 也不例外。
// Objects/tupleobject.c:16
#ifndef PyTuple_MAXSAVESIZE
#define PyTuple_MAXSAVESIZE 20 /*缓存 Tuple 的 size 上限*/
#endif
#ifndef PyTuple_MAXFREELIST
#define PyTuple_MAXFREELIST 2000 /* 每一种 size Tuple 缓存最大数量*/
#endif
#if PyTuple_MAXSAVESIZE > 0
// 缓存数组,保存的是各尺寸 Tuple 链表头
static PyTupleObject *free_list[PyTuple_MAXSAVESIZE];
// 对应尺寸 Tuple 的链表长度
static int numfree[PyTuple_MAXSAVESIZE];
#endif
从定义可知,Tuple 的 freelist 只缓存 size 在 [0, 20] 之间的 Tuple,每一种尺寸最多缓存 2000 个实例。定义看起来不太清晰,看图其实就没多复杂:
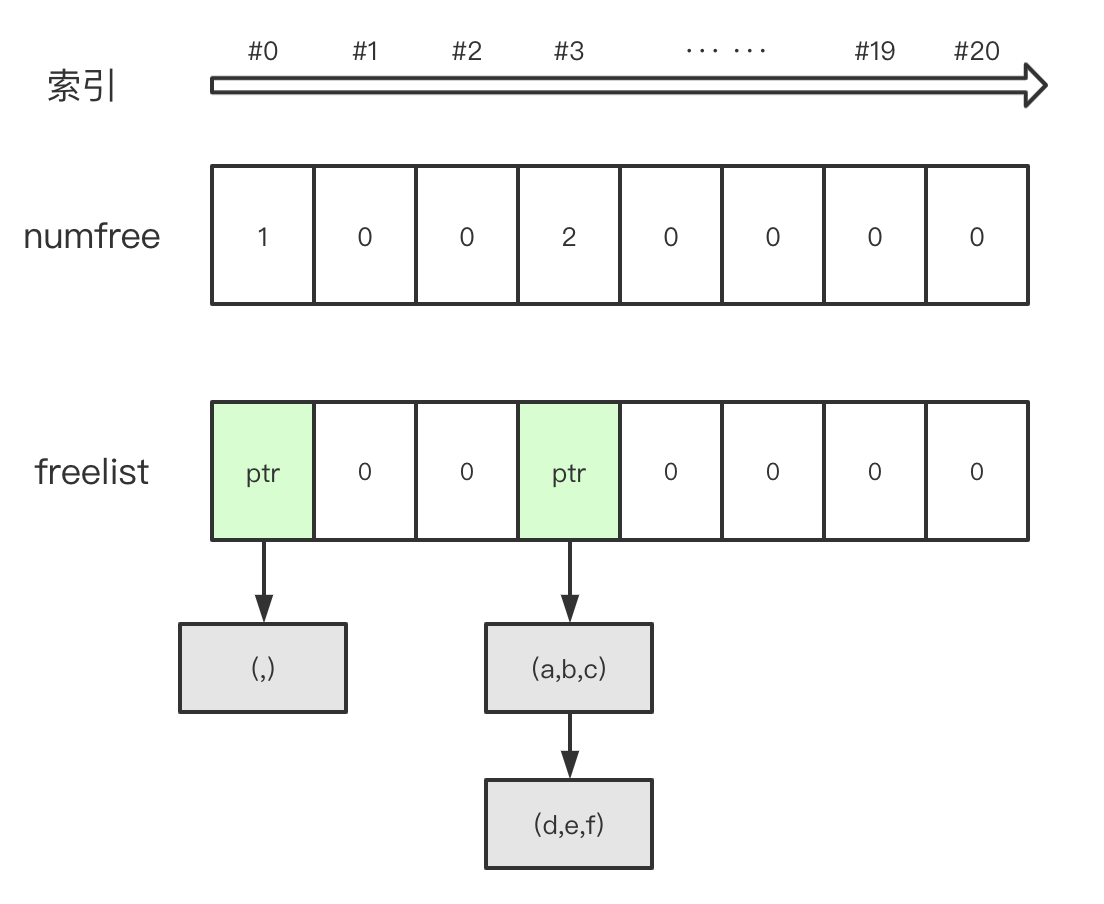
图中索引表示的是 Tuple size,free_list[3] 缓存的是大小为 3 的 Tuple 构成链表的头部, numfree[3] 表示缓存中 size == 3 的 Tuple 数量。
在最开始的时候,freelist 是一个全为 NULL 的数组,没有缓存任何数据。当有 Tuple 被析构的时候,满足 size 在 [0,20],并且 free list 未满的情况下,即将被析构的 Tuple 就获得一线生机进入 freelist,避免了被垃圾回收的命运。
// Objects/tupleobject.c:237
static void
tupledealloc(PyTupleObject *op)
{
//··· ···
// size 满足条件,缓存未满
if (len < PyTuple_MAXSAVESIZE &&
numfree[len] < PyTuple_MAXFREELIST &&
Py_TYPE(op) == &PyTuple_Type)
{
// 插入链表
op->ob_item[0] = (PyObject *) free_list[len];
numfree[len]++;
free_list[len] = op;
goto done; /* return */
}
// ··· ···
}
这里链表的组织特别有意思,并没有在 PyTupleObject 中新增形如 * next 的指针成员,而是直接复用了 Tuple->items[0] 作为链表节点:
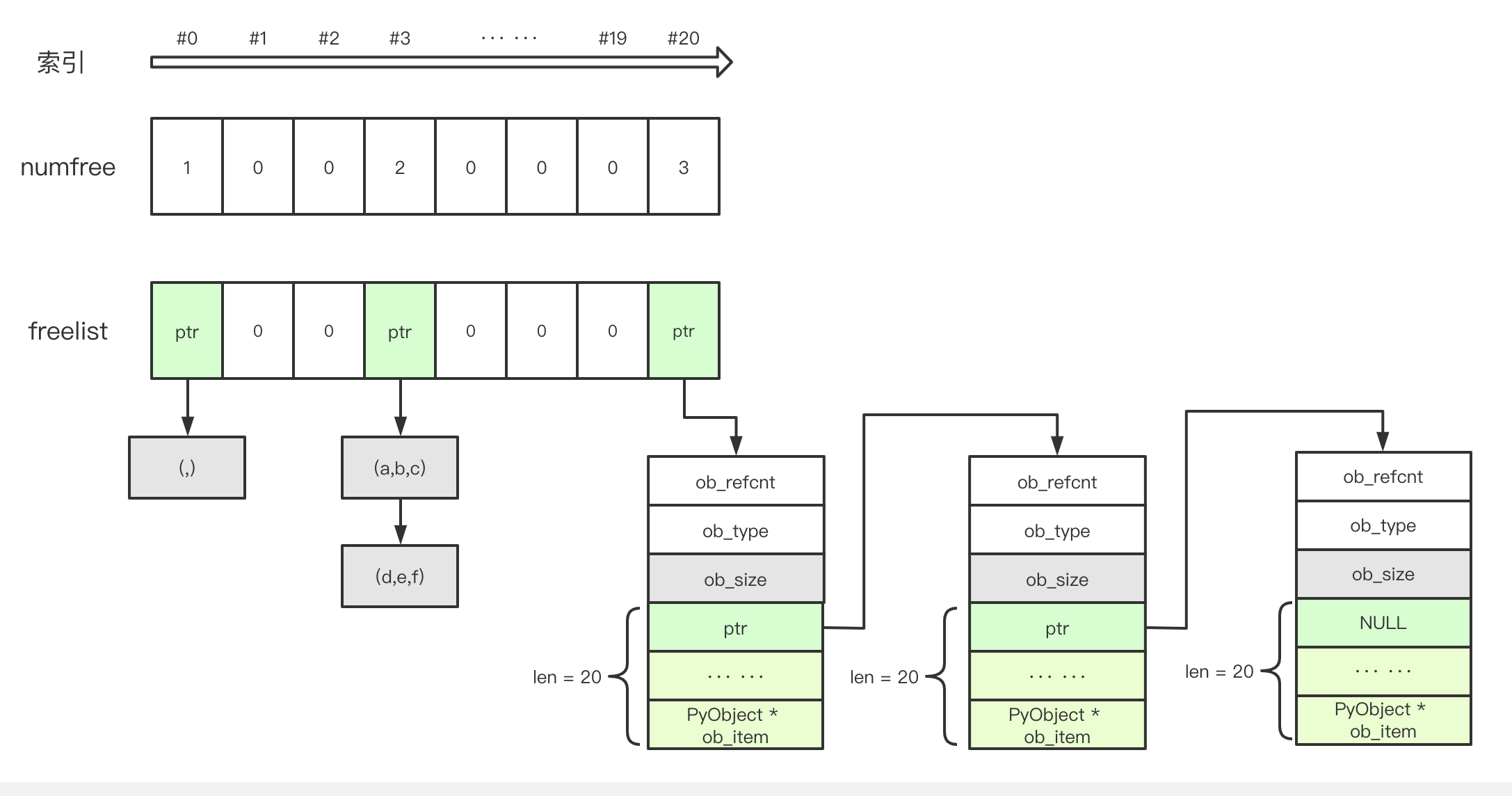
图中将 freelist[20] 链表展开绘制,如果你熟悉链表的操作,结合上面的代码就很容易明白代码的意图。注意 numfree[20] 现在是 3 了,刚好是缓存 Tuple 实例的数量。
你是空,长度为 0 的空空
在 PyTuple_New 函数中有这样的代码:
// Objects/tupleobject.c:89
// size 为 0 的 Tuple 直接使用缓存,先看 125 行再看这里
if (size == 0 && free_list[0]) {
op = free_list[0];
// Objects/tupleobject.c:125
if (size == 0) {
free_list[0] = op;
++numfree[0];
Py_INCREF(op); /* extra INCREF so that this is never freed */
}
在第一次用到 size 为 0 的 Tuple 的时候,该实例被缓存在 free_list[0] 中,并且额外给它增加了一个引用,这样它的引用计数永远也不会减到 0, 可以获得 “永生了”。之后所有空 Tuple 实际上都引用的同一个实例 numfree[0]。
这个非常厉害的空 Tuple 会一直保留到 Python 主动释放它为止。释放过程在 PyTuple_Fini 函数中。
