现在我们至少有这样的认识,ByteCode 是 VM 唯一直接支持的运算表示,Python 源码的复杂逻辑,最终需要转换为 Bytecode。而 Bytecode 又是如此简单,从 Python 源码到 Bytecode 的转换面临着巨大的挑战。虽然我们不打算深入编译原理,但有必要直观的了解 Python 源码是如何转换为一步一步最基本的 VM 操作码的。
识别源码
Python 源码和大多数程序源码一样,它们本质上都是字符串,或者说文本,它们与一本小说,或者这篇文章没有根本的差别。源码是一种面向人类开发者的 “语言”,与一般人类语言类似,也遵循某种文法,只不过更加严格(因为计算机要求语意精确)。这里仅以英文源码说明,不再特别说明其他语言的情况。
单个字母的意义是非常有限的,英语的单词是表达意义的最小单元,Python 在识别源码的时候也是如此,以 “单词” 为单位而非具体的字母。以最简单的 Hello world 程序为例:
print("Hello world.")
实际处理的是类似这样的单词流:
- (
- "Hello world. "
- )
- 换行符
这一阶段是词法处理,Linux 下的开源工具 Lex 或者 Flex 可以轻松的实现这一功能,它会根据正则表达式将单词流转换为一系列 Token。
源码并不是任意 Token 的组合都是有效的,同时需要遵守一些严格的语法要求,我们在编写代码的时候,经常会看到一些语法错误提示,就是文法检查不合格。如果只考虑 Hello world 代码,文法可以简单的定义为:
函数名(字符串)
这样的语法要求,符合语法要求的源码才是有意义的。在 Linux 下可以通过 Yacc 或 Bison 实现文法检查。
从源码到抽象语法书 AST
这里推荐一个在线工具 https://vpyast.appspot.com/ ,可以方便的看到 Python 代码对应的 AST,方便理解。Hello world 程序的结构非常简单:
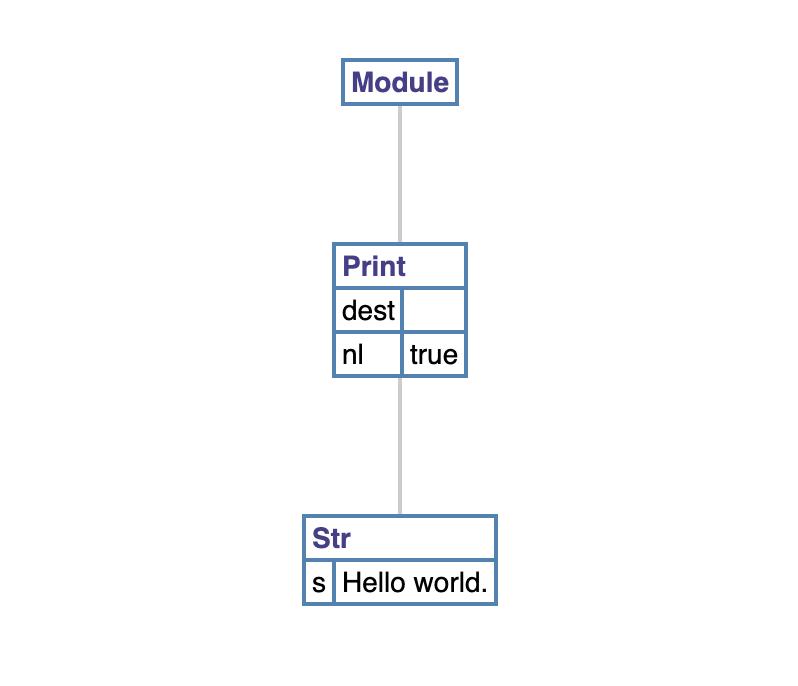
可以看到语法树的顶层是 module,也就是单个 Python 源码在 Python 中被视为独立 module,之后依次是 print 函数和它的参数。这个例子太过于简单,下面是一段包含较复杂数学优先级的代码:
a = 12 + 5 * 6 - 7 /8
这也是大多数编程语言最基本的问题,优先级是如何实现的。我们直接看一下它的 AST 什么样:
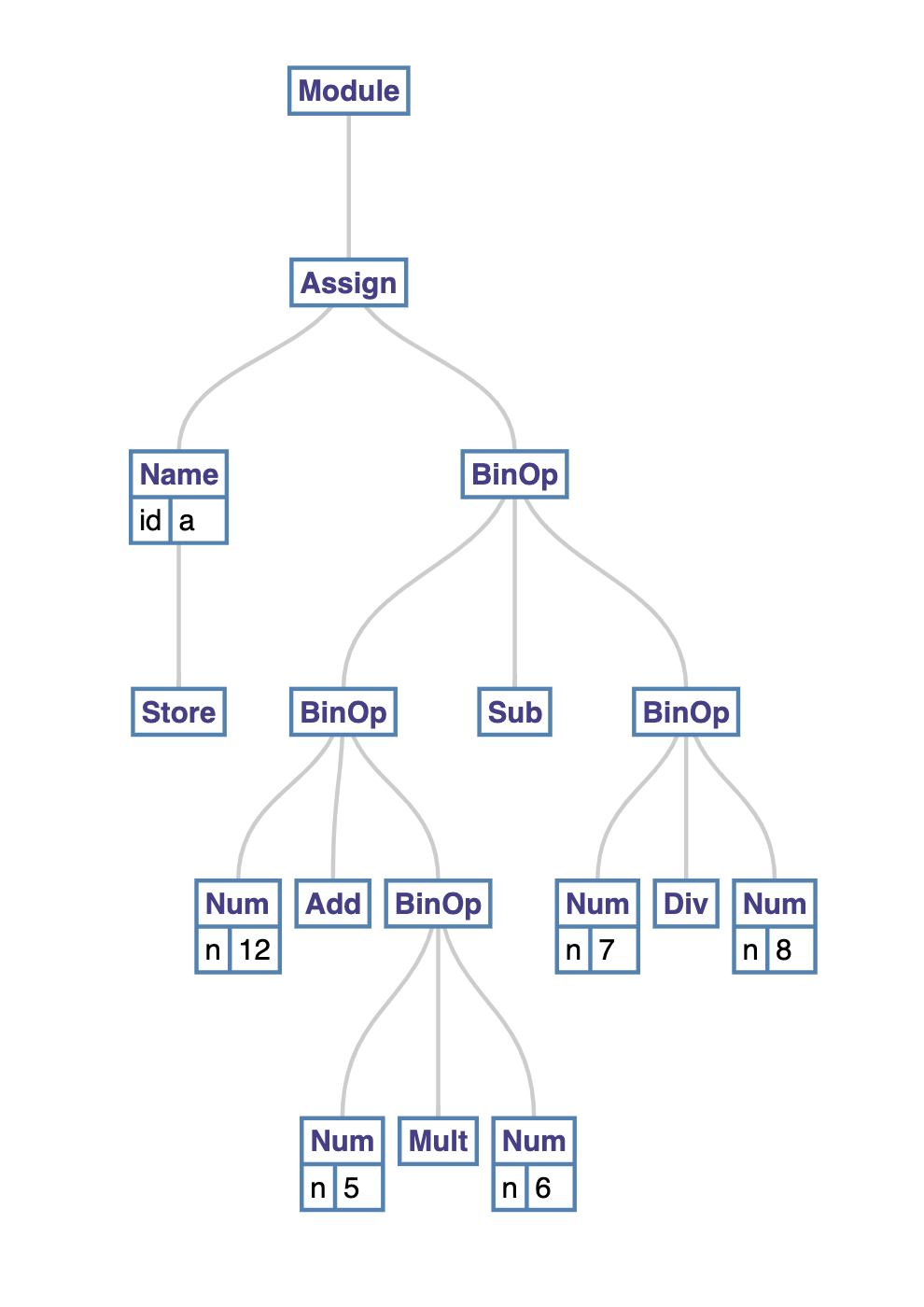
在 module 之后的第一层,可以看到是将某个值赋给变量 a,但是这个值需要对后面的算式计算后才能知道是什么,这是一个临时变量。之后为了计算每一层的值,有可能需要继续乡下一层展开求值,一直到树的每个叶节点都无需再继续展开为止。最终优先级越高的运算越靠近树的下部分。
AST 之所以被称为抽象语法树,主要是因为此时的代码表示已经不包含源码的具体细节了。
仅仅依赖 AST ,只要我们根据广度优先的原则,Bytecode 几乎就是呼之欲出了。让我们从 AST 自下而上的手工编写 Bytecode 伪代码:
- 5 * 6 -> tmp1;
- 12 + tmp1 -> tmp1,让我们复用一些临时变量,算做一点优化;
- 7 / 8 -> tmp2;
- tmp1 - tmp2 -> tmp1;
- tmp1 -> a;
已经很接近 Bytecode 的意思了,这都要拜 AST 所赐。
一点题外话
对于大多数人,编译相关的工作都显得枯燥、神秘,实际上在现代工具的支持下,你可以很容易实现自己设计的编程语言,只需要一点点努力就好,比如这篇文章,就利用 lex 和 yacc 实现了一个简单的计算器。在某些项目中,如果有必要,你甚至可以临时创造一种语言,帮你快速生成一些枯燥的代码,有朝一日名满天下也说不一定。
