前面已经对 AST 的构建、查看、修改比较理解了,AST 可以认为是 Python 源码的另一种表示,它们具备一对一的对照关系,甚至只要提供 AST,我们可以通过 astunparse 之类的库直接从 AST 完美的还原到源码。
从源码到 AST,再从 AST 到源码,它们只是同一种逻辑的不同表示。需要注意的是,在构建 AST 的时候,不需要理解源码的运行逻辑,只是单纯的对源码进行文法分析,就好比将一句话拆分为主谓宾,无论是 “吃草牛” 还是 “草吃牛” 都是符合文法的,但显然第二种说法是毫无逻辑的。构建 AST 完全是对源码的 “静态” 分析,这对后面的理解非常重要。
从 AST 到 ByteCode 的转换在逻辑上并不复杂,但细节却非常繁杂,可以确定的是,看到 AST 的时候,ByteCode 就已经是呼之欲出了,ByteCode 的容身之所就是 CodeObject。
重新审视 CodeObject
让我们再次请出 CodeObject,在前面的章节中我们曾有过一面之缘。
/* Bytecode object */
typedef struct {
PyObject_HEAD
int co_argcount; /* 参数数量,不含可变参数 */
int co_posonlyargcount; /* 位置参数数量 */
int co_kwonlyargcount; /* 命名参数数量 */
int co_nlocals; /* 局部变量数量 */
int co_stacksize; /* 总的调用栈大小 */
int co_flags; /* 一些标识位 */
int co_firstlineno; /* 第一行代码的行号 */
PyObject *co_code; /* 字节码本尊! */
PyObject *co_consts; /* 常量,数组 */
PyObject *co_names; /* 名称,数组 */
PyObject *co_varnames; /* 局部变量名,元组*/
PyObject *co_freevars; /* 闭包中的变量,元组 */
PyObject *co_cellvars; /* 嵌套函数中的局部变量,元组 */
// ··· ···
} PyCodeObject;
真正的 ByteCode 是 co_code 成员,名字就已经出卖了它。当然,其他各参数也是必不可少的,co_names 中保存了所有的变量名,co_consts 则保存了所有的常量, co_stacksize 更是说明了执行这一段 co_code 所需要的栈空间大小。
在 《源码剖析》 中对 CodeObject 的介绍很细致,Python 3.8 相比 2.6 版的 CodeObject 差异不大,有兴趣的朋友可以仔细阅读第 7 章内容。其中的大部分内容我在后面也会逐步涉及,只不过分析思路与陈儒先生会有一些差异。
这里有一个问题,CodeObject 的结构的确如上面所示,这么设计的逻辑是怎样呢?这一点没有在源码注释中看到,仅代表我的个人见解。
重新设计 ByteCode
作为一个侦探,如果想破解一桩悬案,首先要成为凶手。
不如让我们着手设计一个新的 ByteCode 方案吧。我们保留 Python 的栈式 VM 架构,仅仅设计新的 ByteCode 即可,看看能不能有什么发现。从最简单的任务开始:向变量赋值。
# 这是两各变量的赋值
a = "hello"
b = "hello"
忽略一些无关的部分,这两行代码可以转换为下面的汇编(暂时就叫它汇编吧,一种二进制指令的字符表示,只比字节码高等一点点):
LOAD_CONST 'hello'
STORE_NAME "a"
LOAD_CONST "hello"
STORE_NAME "b"
刚好,两行赋值的源码各产生 2 行汇编代码。为了压缩 ByteCode 的体积,肯定不能直接保存这种汇编代码,我们来设计一个。
方案 1
汇编代码中包含两种数据:
- 操作名: LOAD_CONST、STORE_NAME;
- 参数: "a"、"b"、'hello';
首先设定第一个转换规则:
移除汇编代码中的空白行,用分号分割操作符和参数,并且用分号代替换行,让所有的汇编代码成为一个长字符串。
LOAD_CONST;'hello';STORE_NAME;"a";LOAD_CONST;"hello";STORE_NAME;"b";
这种方案下,字节码呈现出:操作名;参数;操作名;参数··· ··· 这样的序列。
有一个问题,如果没有参数怎么办?凉拌!空着就好了,比如:
LOAD_CONST;;
在 ByteCode 的实际实现中,也确实使用了类似的方案,简单而有效,后面分析到的时候我会提示这一点。
这种方案已经比最初的汇编代码有了很大的改善,但依然有优化的余地,毕竟搞我们这一行,优化无止尽!
优化方案 2
所有 CPU (VM 也是一种虚拟 CPU)都有固定的指令集,Python 的操作名数量是固定的,所以我们完全可以对指令编号,这样就不需要在 ByteCode 中明文存储指令名了.
继续增加一个规则:
操作名转换为对应的操作码(opcode)。
两个操作名实际上的编号分别是:
- LOAD_CONST: 100
- STORE_NAME: 90
那么我们的 ByteCode 方案会变成这样:
100;'hello';90;"a";10;"hello";90;"b";
已经简短了很多嘛,微小的优化,客观的进步!
优化方案 3
如果自己观察方案 2 中的 ByteCode,看到了吗?‘hello’ 字符串出现了两次,既然都是一样的字符,第二次出现的时候完全可以说 “这里的参数跟前面某处指令一样”。好了,那就再增加一条规则吧:
可以通过一个索引号,引用前文的值,为了区分,我们在这个索引前加一个特殊的符号 ‘L’。
(其实增加特殊字符 L 这种表示方案是不可靠的,请领会精神,反正我们也不真的使用这种方法。)
再看看 ByteCode 看起来如何:
100;'hello';90;"a";10;L1;90;"b";
可以看到第二个 ‘hello’ 的地方改成了 L1,我们的 ByteCode 又精简了一些。那么不如更近一步,将最后一条规则改为:
所有的常量、名称都储存在单独的数组(元组)中,参数直接使用其索引。
实际上这已经非常接近 Python 的方案了,下面是再次优化的表示:
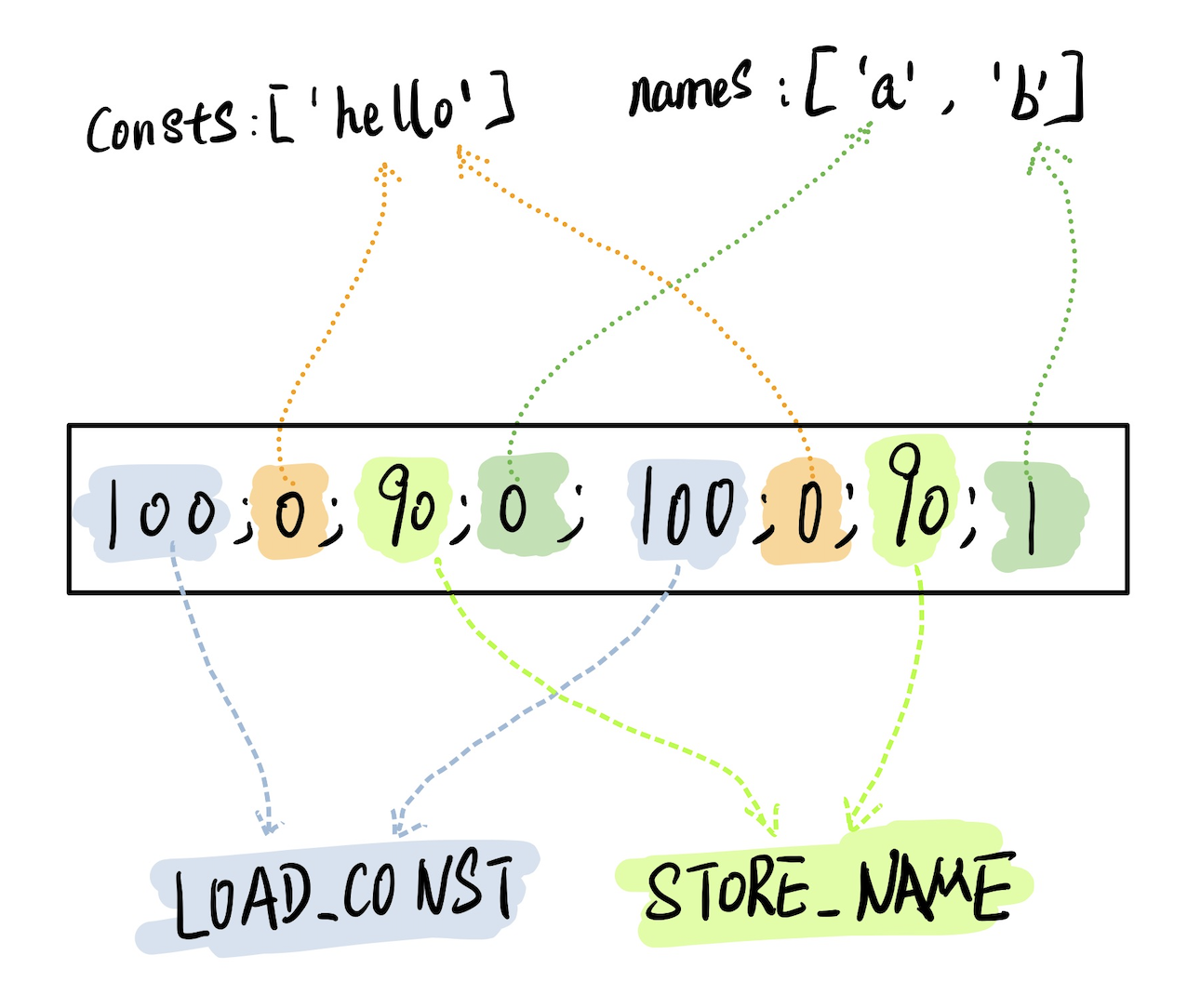
consts: ['hello']
names: ['a', 'b']
code: '100;0;90;0;100;0;90;1'
附上对应的图示:
So, why CodeObject?
方案 3 已经非常接近 Python CodeObject 的形态了,在很大程度上,CodeObject 的结构是为了获得更加紧凑的结构,否则单独考虑 ByteCode 的表示,方案 1 是最直接的,方案 1 确实与 dis 库反汇编 co 的输出形式非常接近。
在逻辑上 CodeObject 提供了一种更加紧凑的 ByteCode,也给了其他静态参数容身之地。实际上 CodeObejct 的设计也考虑到了后面 FrameObject 的实现,比如采用独立的成员分别保存 Consts 和 Names,正好 FrameObject 直接引用即可。
Python 的 CodeObject 设计通盘考虑了 ByteCode 的紧凑性,以及到了运行时 VM 处理的便利性,在设计上,达成一种统一和谐的境界。
