终于,解决了变量的作用域问题,AST 中的信息也被整理妥当,下面让我们进入正题,生成 CodeObject。
再看 CodeObject 的结构
构建 CodeObject 的过程,实际上对应着低级语言(如 C、C++)的编译链接。如果有汇编经验就会知道,在 Intel x86 平台上的可执行程序可以分为 data segement、code segement:
程序中的数据和代码是分开的。CodeObject 也采用类似的策略,由于 Python 是一种高级抽象的编程语言,CodeObject 中不止存在保存常量的 co_consts 列表、二进制字节码 co_code,还有所有的名称 co_names,这些信息和其他运行时相关的属性,共同构成了 CodeObject 对象。CodeObject 的结构远比二进制可执行文件的结构更复杂,它在逻辑上不是简单的线性排列,而是一个复杂的对象。
/* Bytecode object */
typedef struct {
PyObject_HEAD
int co_argcount; /* 参数数量,不含可变参数 */
int co_posonlyargcount; /* 位置参数数量 */
int co_kwonlyargcount; /* 命名参数数量 */
int co_nlocals; /* 局部变量数量 */
int co_stacksize; /* 总的调用栈大小 */
int co_flags; /* 一些标识位 */
int co_firstlineno; /* 第一行代码的行号 */
PyObject *co_code; /* 字节码本尊! */
PyObject *co_consts; /* 常量,数组 */
PyObject *co_names; /* 名称,数组 */
PyObject *co_varnames; /* 局部变量名,元组*/
PyObject *co_freevars; /* 闭包中的变量,元组 */
PyObject *co_cellvars; /* 嵌套函数中的局部变量,元组 */
// ··· ···
} PyCodeObject;
如果你愿意,也可以将 CodeObject 内的各种属性分为可执行部分 co_code 和其他数据。
CodeObject 的构建过程在逻辑上并不复杂,只需要深度优先遍历之前的 Symbol table,按部就班的转换为对应的二进制字节码就可以了。这其中对 co_consts、co_names 之类数组的处理,很大程度上是对代码中的 “常量” 部分缓存,提高存储效率。它们会按照出现的次序在各自数组中占据未知,字节码中用其在数组中的索引号访问他们。
Scope 的实现
深度优先遍历难免会遇到一种情况:递归。Python 允许代码块的嵌套,虽然 CodeObject 的结构比较复杂,但是 CodeObject 本身并不是嵌套结构,这就出现一个矛盾:子代码块(如函数、类)如何表示?
答案是隐藏在 co_consts 中。在陈儒先生的《源码剖析》,函数代码块在 CodeObject 的实现没有太过深入说明,这里稍作解释。
当 Python 的 “编译” 进行到 run_mod 函数,此时 Symbol table 构建完成,各代码块的变量作用域之类的运行时信息也已经就绪,就由 compiler_mod 接收,正式开始构建 CodeObject 对象,即最终的编译工作。
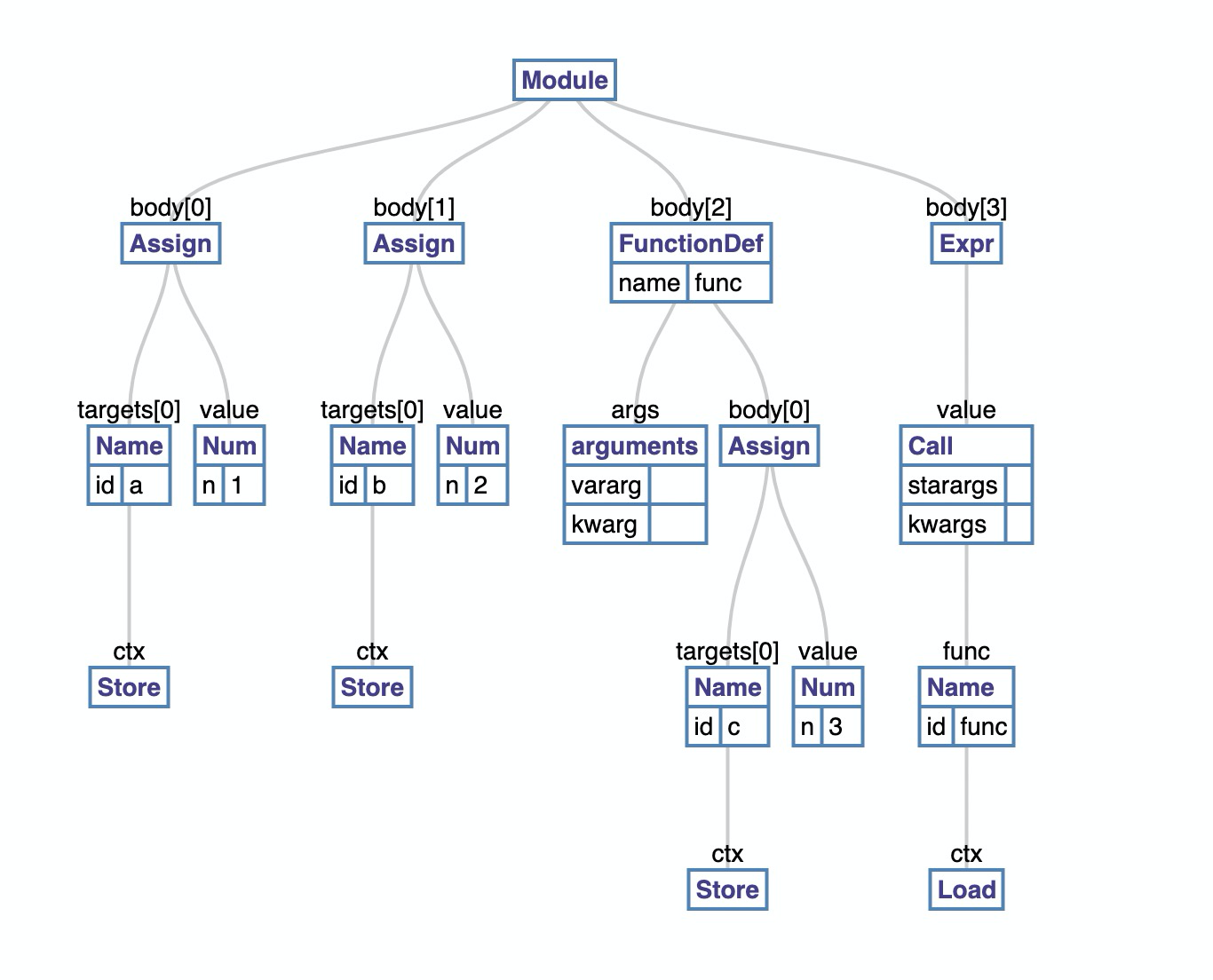
上图是下面代码的 AST:
a = 1
b = 2
def func():
c = 3
func()
我们知道 Python 源码的最顶层为 “Module”,源文件中的语句则按照出现顺序,依次追加到 Module 的 body[1\2\3\4]。生成的字节码很容易根据 AST 创建,记住 Python 是栈式虚拟机:
# a = 1
LOAD_CONST 1
STORE_NAME 'a'
# b = 2
LOAD_CONST 2
STORE_NAME 'b'
# def func ··· ···
LOAD_CONST ??
STORE_NAME 'func'
# func()
LOAD_NAME 'func'
CALL
除了函数 func 的处理外,其他的字节码生成过程是显而易见的(当然,实际的生成过程依然充满挑战)。
前面的 Python 代码中有个函数 func 的定义,Python 中一切都是对象,func 函数的定义不应当被看作多行代码,在 Module 这个层面:
def func():
c = 3
实际上等同于类似这样的代码:
func = lambda: c = 3
当然,这样的代码是不正确的,我所要表达的是, def 指令是将一个函数对象绑定到 'func' 上,就想 a = 1 是将一个整数对象与名称 'a' 绑定在一起一样,对于 Python 它们二者是类同的。
现在的问题是,
# def func ··· ···
LOAD_CONST ??
STORE_NAME 'func'
这里的 '??' 到底是什么。让我们去源码中寻找答案。
前面已经提到 run_mod 函数,它将会完成 CodeObject 的生成和执行两个任务,CoceObject 的生成由 compiler_mod 完成,之后由 execute_mod 执行。
现在我们的重点关注目标是 compiler_mod。
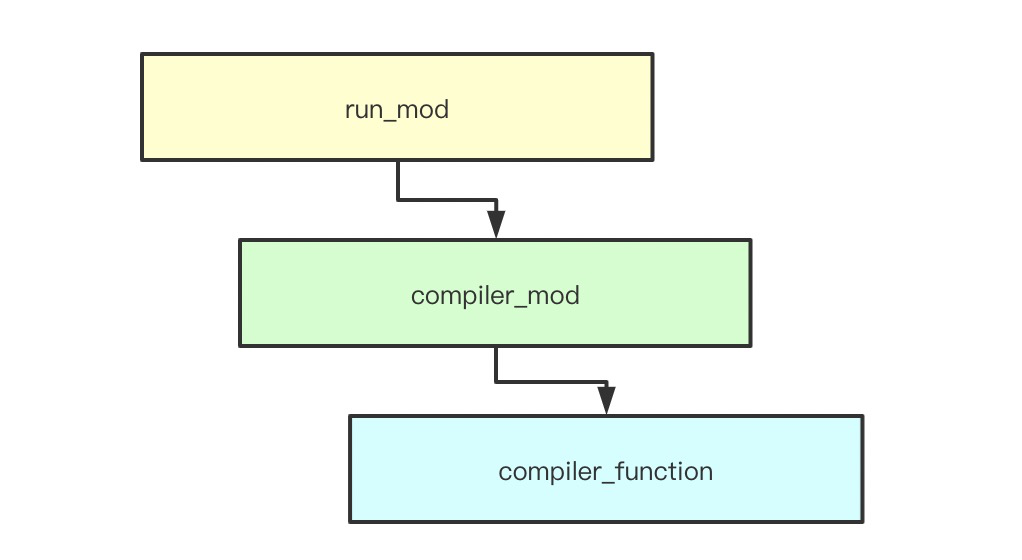
沿着 compiler_mod 的调用栈一路跟进,函数定义最终由 compiler_function 处理。
// Python/compile.c:2129
static int
compiler_function(struct compiler *c, stmt_ty s, int is_async)
{
// ··· ···
// 切换到函数 scope
if (!compiler_enter_scope(c, name, scope_type, (void *)s, firstlineno)) {
return 0;
}
// 编译函数的 body,获得函数代码的 CodeObject 对象
VISIT_SEQ_IN_SCOPE(c, stmt, body);
co = assemble(c, 1);
// ··· ···
// 返回上一级 scope
compiler_exit_scope(c);
// ··· ···
// 将函数的 co 添加到 scope 的 consts 数组中
compiler_make_closure(c, co, funcflags, qualname);
// ··· ···
}
函数被先编译为 CodeObject,然后添加到定义函数的 scope 的 consts 数组中。
需要注意一点,字节码的编译实际上分两步走:
- 先编译为 struct instr * 数组;
- 再将 1 转换为字节码,进一步组装为 CodeObject。
assemble 函数完成了步骤 2 的工作。
回到前面的例子,在处理 func 的时候会调用 assemble 生成 func 的 CodeObject,但此时整个 Python 文件的 Module 还处于 1 中的状态。这里有一个比较反直觉的实际,CodeObject 是由代码块嵌套层次自下而上生成的。
先生成了 func 的 CodeObject,最后才在 compiler_mod 结尾的 assemble 结束了 CodeObject 的生成。

在 compiler_mod 接近尾声的时候,查看 Module 中的 consts 内容,可以看到其中的
这正是 func 函数的 CodeObject。
总结
CodeObject 的组装过程就是填充 PyCodeObject 的过程,这个过程比较直白,就不再深入挖掘。现在我们知道了,在一个 CodeObject 的 consts 域中隐含着其子代码块的 CodeObject。
在研究中还注意到,Python 在进入嵌套代码块的时候,必定会调用 compiler_enter_scope,全局搜索该函数的调用者可知,Python 中会进入 scope 的情况有:
- Module,也就是进入 Python 源码文件就是一个 scope;
- 函数;
- class;
- lambda;
- comprehension,推导式;
推导式竟然也是独立的 scope,这算是意外收获。
至此,CodeObject 有关的大多数秘密都已经大白于天下,更多的细节还需要后面结合具体的情景分析,因为 Python 的实现真的是繁杂至极。
