今年 AI 发展迅速,尤其是 LLM 涌现出了爆款应用 “ChatGPT”,不会整两句 GPT 你都不好意思扫共享单车。但是由于 OpenAI 的服务限制,国内访问比较困难。再加上自己的问题多少会有一些隐私问题,如果让云厂商知道我账户里的好几千巨款,心里不踏实。信息放在云端远不如运行在本地放心。
感谢伟大的开源社区,Meta 开源了 Llama2 模型,据社区测评,在多数维度可以接近 ChatGPT 的效果。后来 Github 有热心大神开发了 llama.cpp,让 LLM 运行在本地 CPU 上成为现实。llama.cpp 项目的编译安装都非常简单,如果你是个程序员,会很熟悉 ./configure && make && make install 三部曲。从 llama.cpp 开始折腾还是需要点耐心,想快速尝鲜的话,推荐 GPT4All 这款应用。大概看了下,它应该就是 llama.cpp 的 UI 版。
安装 GPT4All
GPT4All 支持 Linux、Mac、Windows 平台,前往官网 https://gpt4all.io/index.html 下载安装适合自己平台的版本。

如果需要设置代理和本地缓存目录,请点击 Setting。点击下一步。
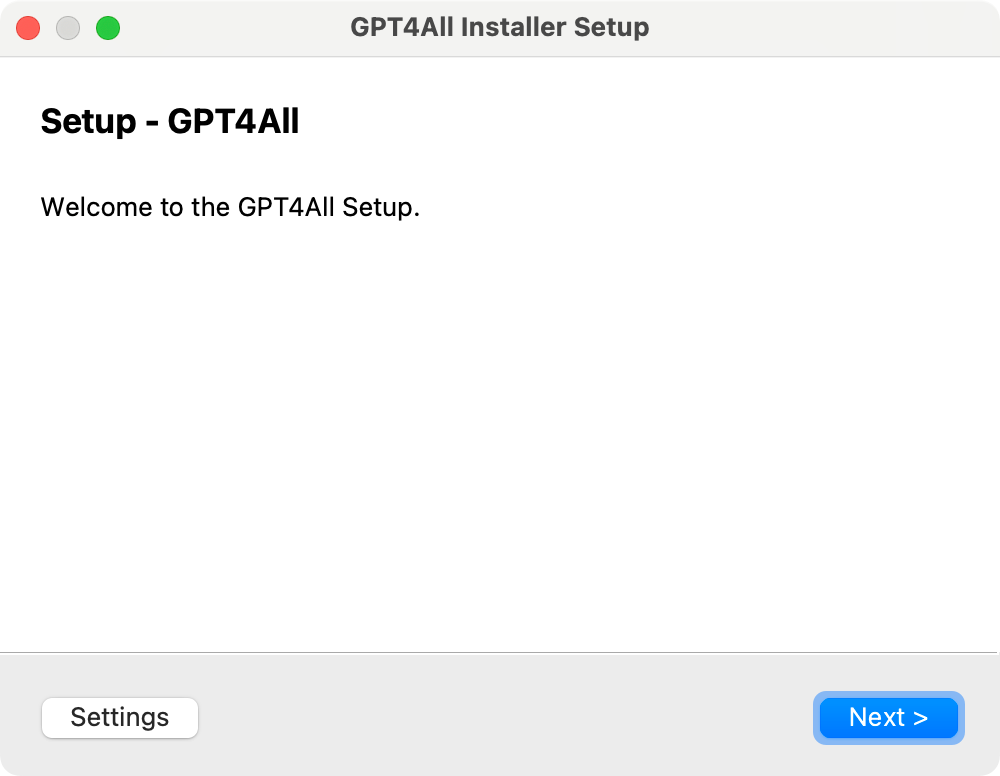
请浏览选择安装路径,因为我打算把模型文件下载到 GPT4All 子目录,一般一个中小型模型大约在 10G 左右,所以最好安装磁盘剩余空间充足。
点击下一步。
每个软件都有的许可协议,勾选同意,继续下一步。
点击 Install,正式开始安装。
安装过程需要十分钟左右,取决于你的网速。
安装完毕。
安装模型
GPT4All 内置了一些训练好的模型,可以通过 GPT4All 下载使用。
这里先说一下如何打开 GPT4All,Mac 下安装好后会看到这两个图标:

请点击右侧图表 gpt4all 启动。左侧为管理工具。
Windows 下开始菜单里似乎只有左边的 maintenance tool,GPT4All 的本体需要去安装目录/bing/ 下找 chat.ext。总之非常诡异,可能这就是所谓的 “工程师文化”,不管你用户的死活。
如果你顺利的找到 GPT4All 的启动图标,第一次启动会看到这个页面,提示你下载模型文件。这是因为 GPT4All 只是模型框架,需要模型文件作为初始化参数。
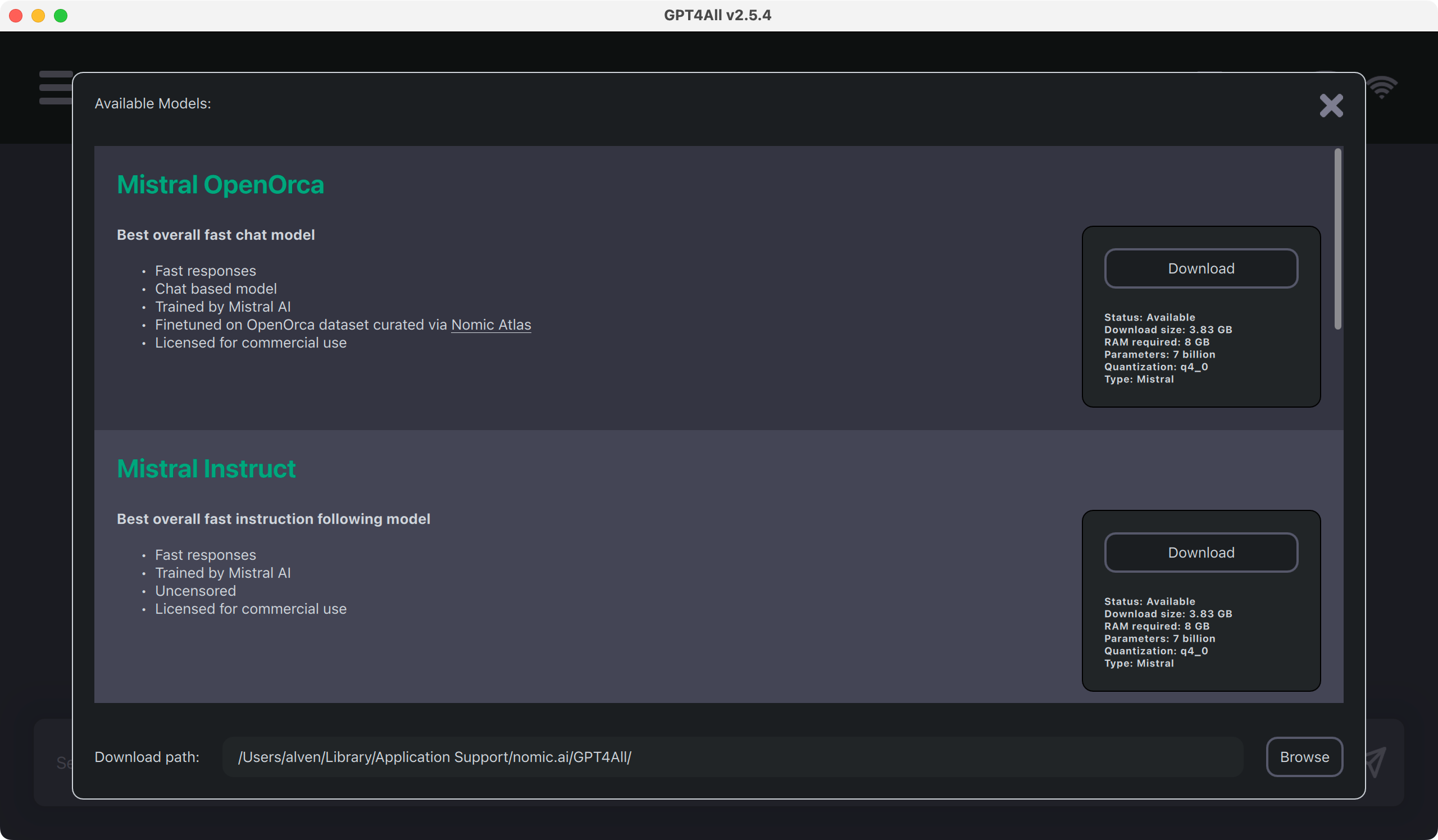
亲测 OpenOrca 还可以,其他部分模型准确度很差。
下载前,点击最下面的 Browse,重新选择模型保存目录,为了方便,请在 GPT4All 安装目录下新建 models 目录,并将其选定为模型下载目录。
点击 OpenOrca 的 download,耐心等待下载完毕。
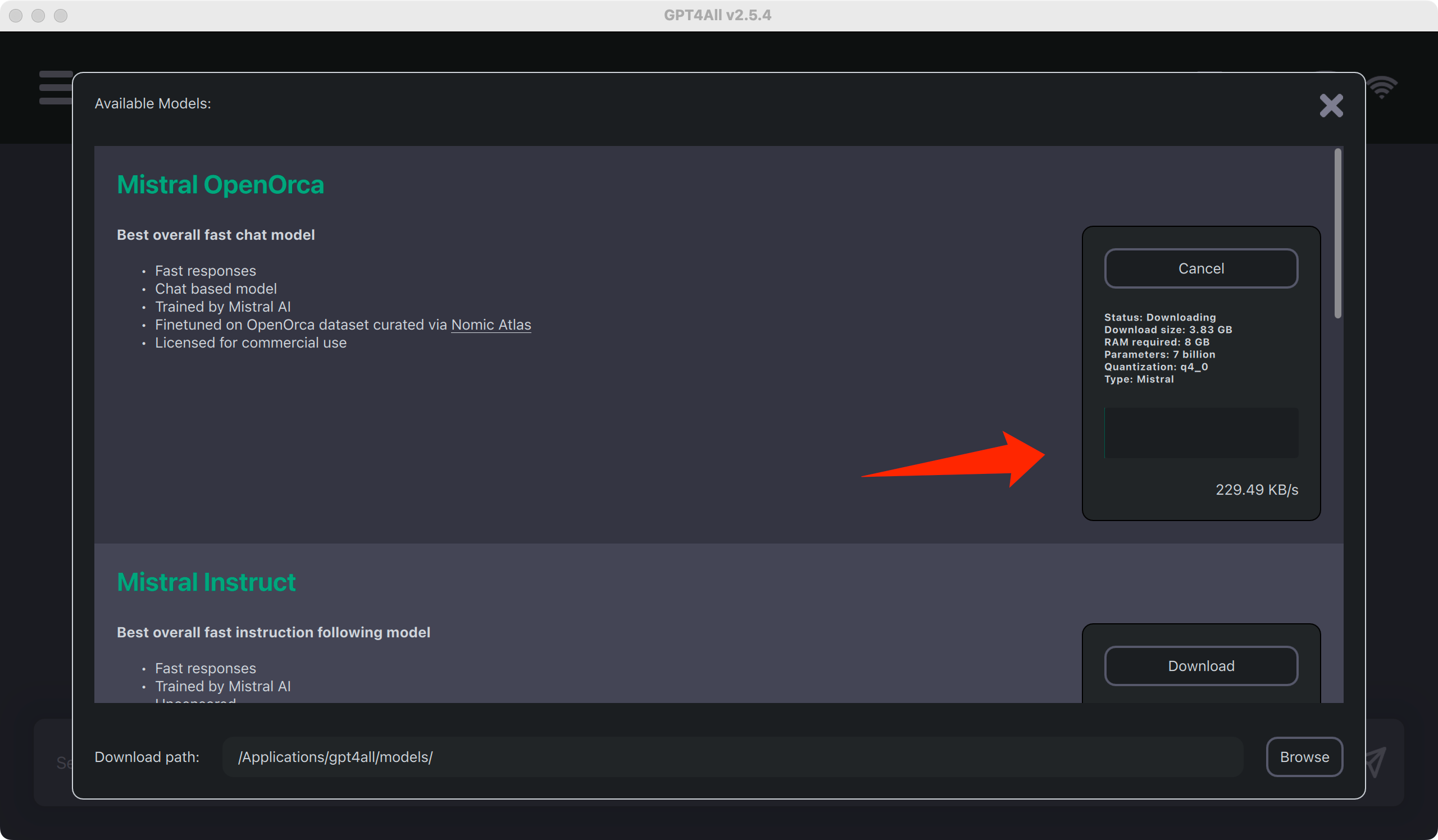
下载完毕就可以进入对话,与 AI 畅聊。由于这些模型的训练输入主要是英语,所以对中文支持不怎么样。虽然是基于 CPU 实现推理,但也能达到 5 Tokens 每秒,还在可以用的程度。
进阶
前面提到 GPT4All 应该是 llama.cpp 的 UI 版,所以它也支持的模型类型和 llama.cpp 是一样。除了从 GPT4All 自带的模型库选择不多,我们也可以自己从 huggingface 找到大量训练好的模型,放到前面设置的模型下载目录 models,GPT4All 也可以加载运行。
注意,模型需为 gguf 格式。
huggingface 访问速度很慢,模型又动则七八 G,推荐一个国内镜像 https://hf-mirror.com/ 下载速度可达 MB/s。
总结
试用了三四个模型,包括一个国内某大学训练的中文模型,与 ChatGPT 还有很大的差距,应该是我的电脑能力有限,最多只能跑 7B 的 llama,再加上社区训练的模型数据量和调优没法和 OpenAI 匹敌,果然 AI 时代,数据为王。如果想在本地获得比较好的使用效果,还需要针对自己的需求继续调教模型。现阶段,个人使用还是推荐云厂商的 GPT 产品,数据更新及时,有超算支撑,使用体验更好。
