开发者通常为了提高内存使用效率,或者避免内存泄漏,需要将内存池化管理。稍复杂一点的系统,一般都会有自己的内存管理机制,我在研读源码的时候,比较习惯先看内存管理模块的实现,这块很见开发者的基本工和工程思想,颇有一叶知秋之感,一个内存管理一团乱麻的系统,注定不会是艺术品。 内存池的实现方法很多,但万变不离其宗,通常就是一次申请大块内存,进程再将其化整为零的重复使用,对于操作系统来说,只发生了少数几次内存分配调用,避免长时间运行后内存碎片化。当内存池耗尽时,可以再申请一大块内存入池,实现内存池扩容。比较常见的是进程私有内存池,共享内存如何实现池化呢?
共享内存的原理
我们通常认为的内存地址,实际上并不是物理内存上的位置。操作系统出于安全性和效率考虑,每个进程都有独立的虚拟地址空间,A 进程的 0X123 和 B 进程的 0X123 处的数据通常没有任何关系。
本文均以 X64/X86 架构为例。
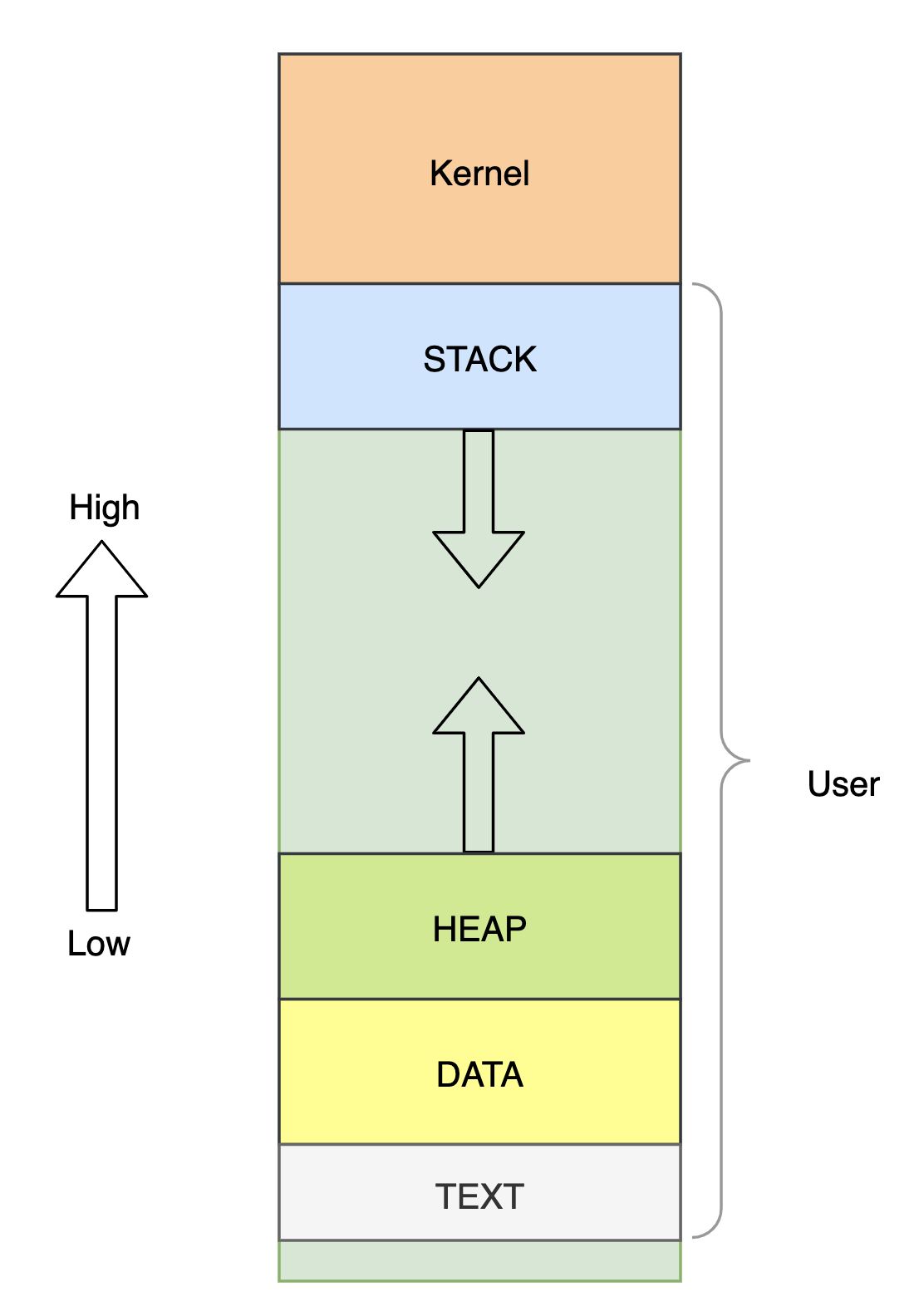
Linux 系统中,所有进程看到的地址空间大体如图,低地址处通常为用户程序,高地址处为内核空间。这个地址空间在不同 CPU 下也有一些差异:
- 32bit 系统中,虚拟地址空间总大小 4G,其中 1G 为内核区域。
- 64bit 系统中,只使用了 48 位地址,因此虚拟地址空间总大小为 256T,通常 8T 为内核区域。
64bit 系统的的进程虚拟地址空间非常大,普通计算机只能用到其中一小部分,操作系统通过 MMU 将虚拟地址映射到真实的物理内存上,这样只需要很小内存,也能同时运行大量程序。
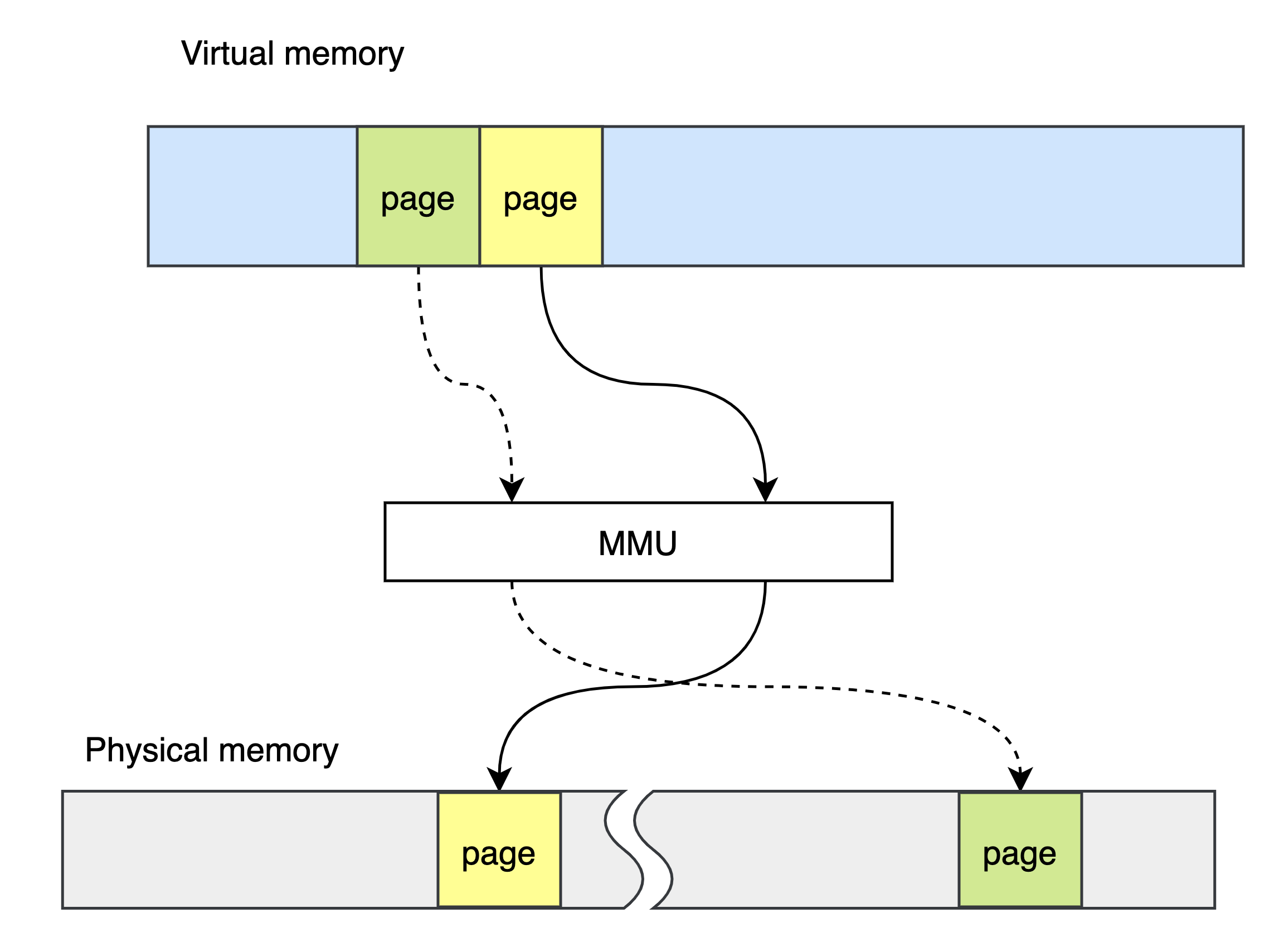
在虚拟内存中地址连续的页面,在物理内存上的地址是不确定的,甚至在不同时刻,相同的虚拟内存地址也会被映射到不同的物理地址。
如果把同一块物理内存映射到两个进程的虚拟地址会发生什么呢?
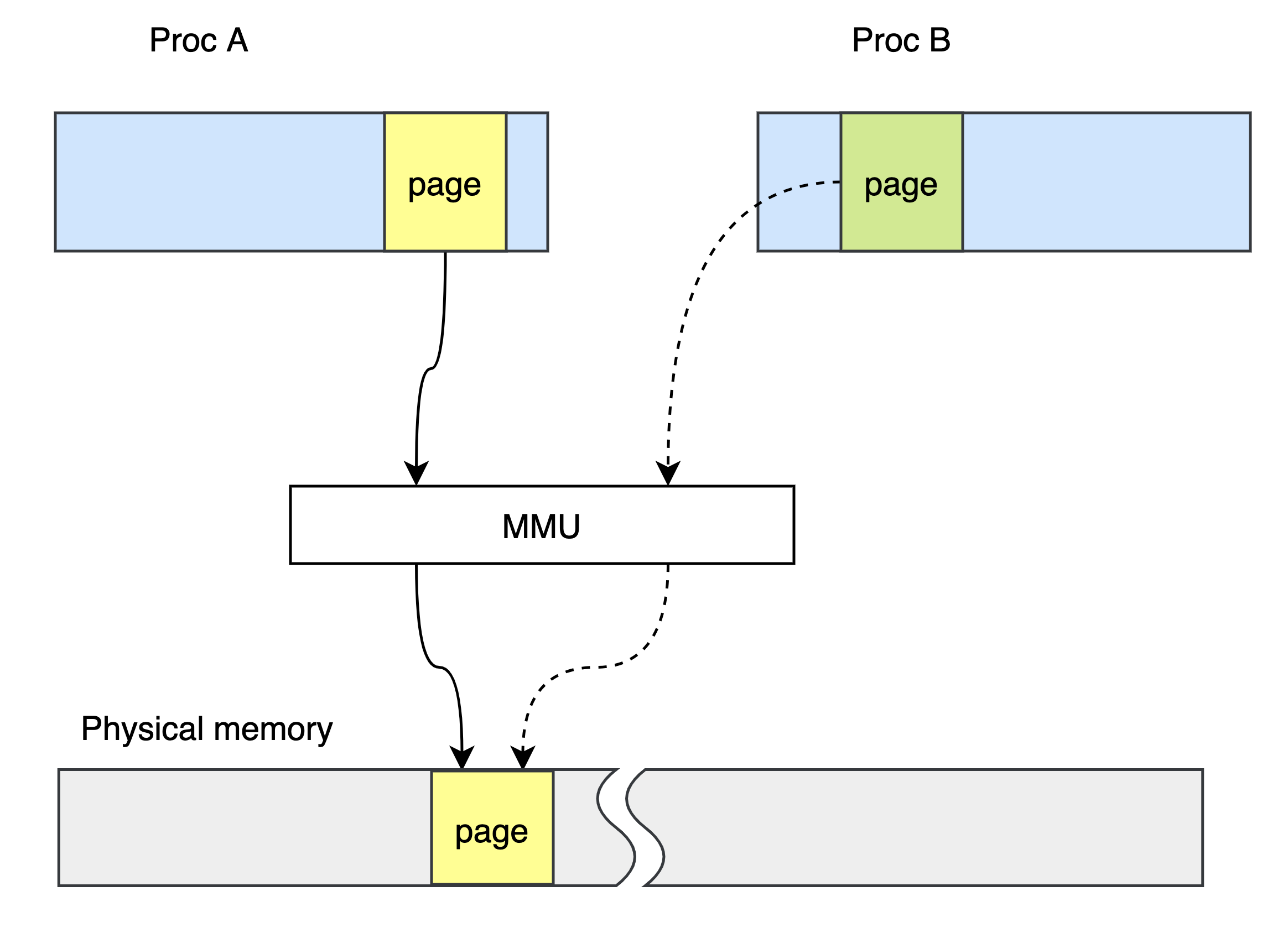
任何一方修改这块区域,另一方都能立刻看到,因为它们实际上是相同的物理内存。但是请注意,这块物理内存区域在两个进程的虚拟内存中的地址却不一定相同。除非两个进程有亲缘关系,一个进程从另一个进程完整的继承了共享内存的映射关系,否则一般来说,同一块共享内存在不同进程中的地址是不同的。
抽象共享内存指针
对于没有亲缘关系的进程们,同一块共享内存通常会映射到各自虚拟内存的不同地址。显然进程之间无法共享虚拟内存地址,我们需要一种通用方法,描述共享内存中的位置。其实内存地址本质上是指针到 0x00 的偏移,我们可以稍作修改,创造一个全新的概念 “共享指针”,它也是一个偏移,但其基准地址是这块共享内存的虚拟内存地址。
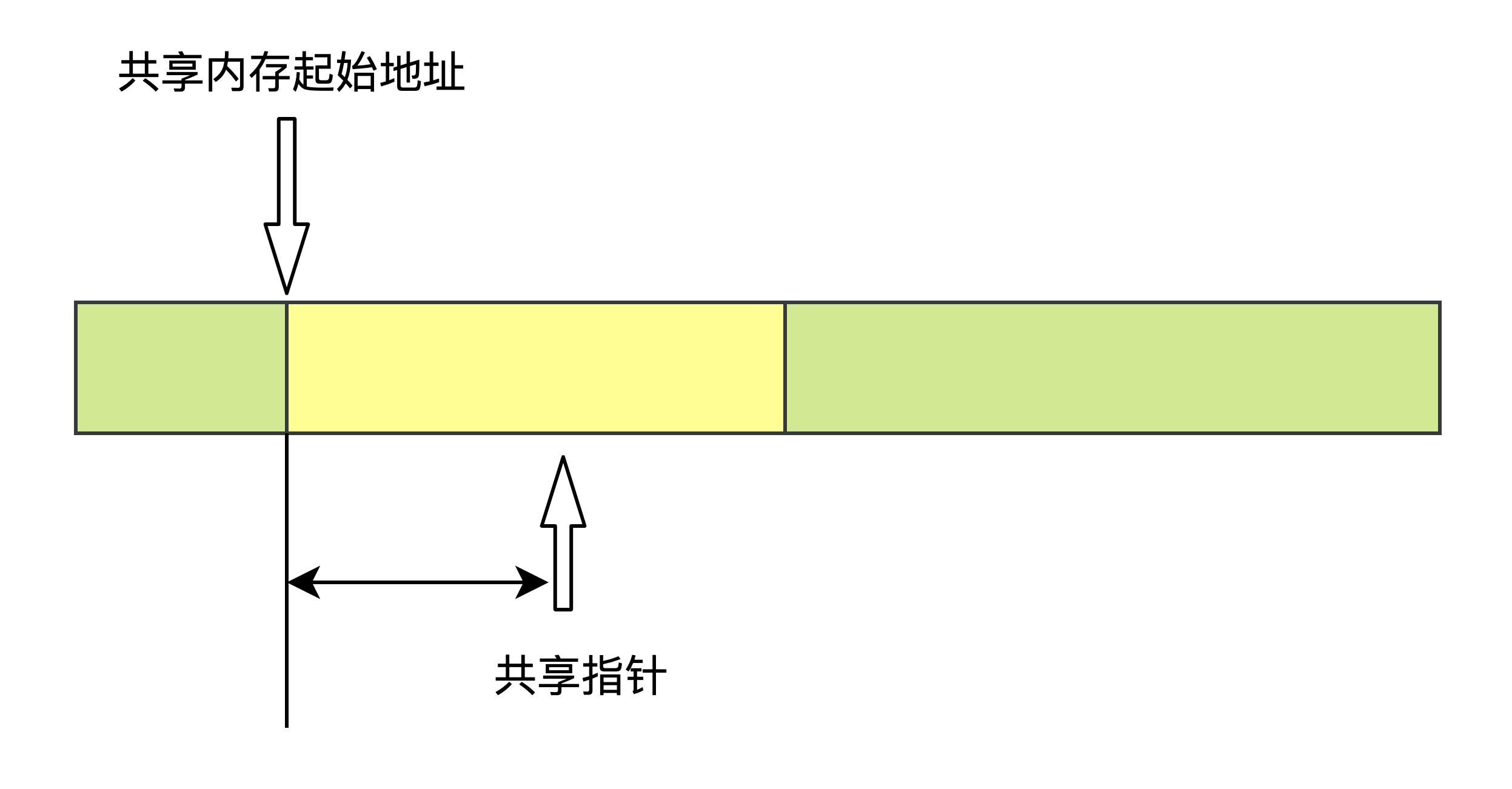
无论在哪个进程,我们都可以通过共享指针,即相对共享内存起始位置的 offset 定位到相同位置,就算各进程共享内存的映射地址(起始地址)不同也没所谓。
很容易得到这样的公式:
共享指针的在进程中的真实地址 = 共享内存基址 + 共享指针(也就是 offset);
共享指针 = 共享指针的在进程中的真实地址 - 共享内存基址;
只要将共享内存中所有指针都改为 “虚拟指针”,那么所有进程都可以将 “虚拟指针” 转换为自己虚拟内存中的地址正确访问。
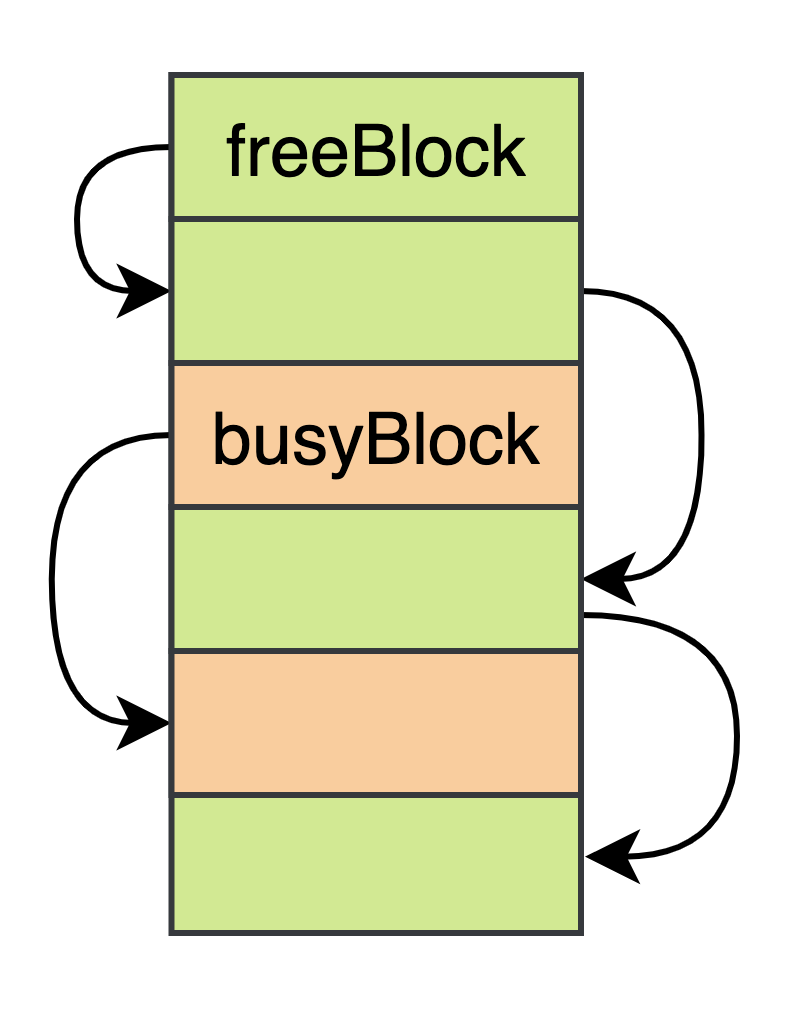
共享内存就可以被切一组 block,通过一些 “共享指针”,把空闲 block 管理起来。
动态扩展
Linux 系统常见的 3 中动态内存接口:
POSIX
- shm_open 函数创建。
- ftruncate 设置大小。
- 通过mmap 将其映射到进程的地址空间,返回一个指针。
- munmap 解除映射。
- shm_unlink 删除共享内存对象。
System V
- shmget 函数。
- shmat 将共享内存段附加到进程的地址空间,返回一个指针。
- shmdt 从进程的地址空间分离该共享内存。
- shmctl 支持其他操作,如删除共享内存段。
mmap 匿名内存映射
无论哪种方式,都无法自动调整共享内存大小,有没有可能创建可以动态调整大小的共享内存池呢?前一步我们已经可以将一块共享内存按 block 管理起来,我们只需要再多申请一块共享内存,把它切分后就是一些 block 了。当所有进程都可以看到第一块共享内存的时候,如何找到新增的共享内存呢?
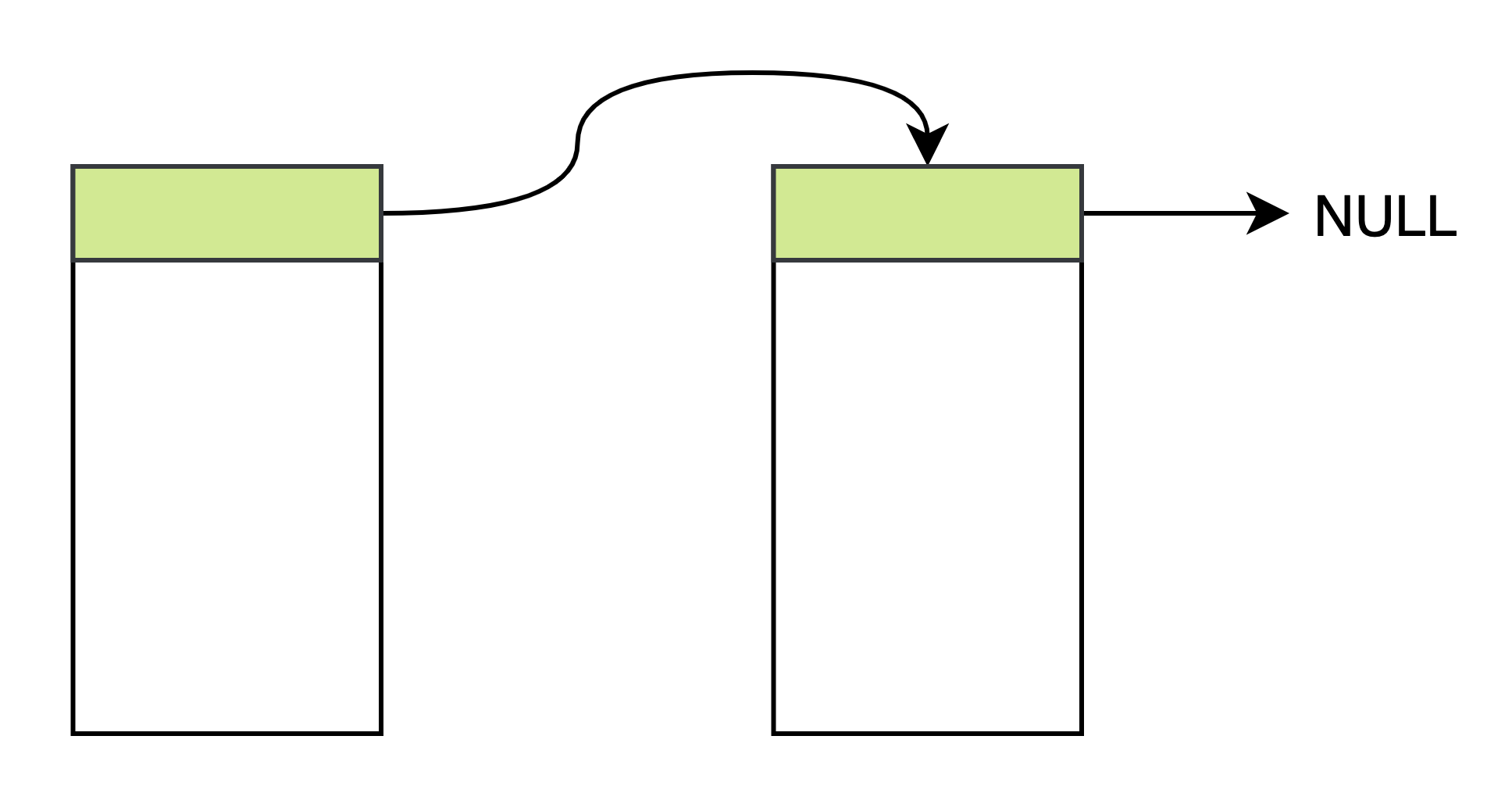
我们只需要在每块共享内存的特定位置,比如开始处,保存下一个共享内存的挂载参数,SystemV 接口就保存 shm key 和 size,POSIX 就保存 name 和 size,用全 0 值表示结束。 逻辑与单向链表类似,只不过通过共享内存参数而非指针串联起来。
前面我们引入一层抽象:“共享指针”,以统一的形式对所有进程描述共享内存中的位置,实际上就是共享内存中的 offset。现在情况变得复杂一点,单纯依靠 offset 已经不足以定位共享内存中的位置,还需要区分是在哪个共享内存上。是时候让 “共享指针” 变得复杂一些。
如果你对网络地址比较熟悉,应该听说过 “子网掩码”,我们也可以将 “共享指针” 的地址空间划分为共享内存编号 + offset。
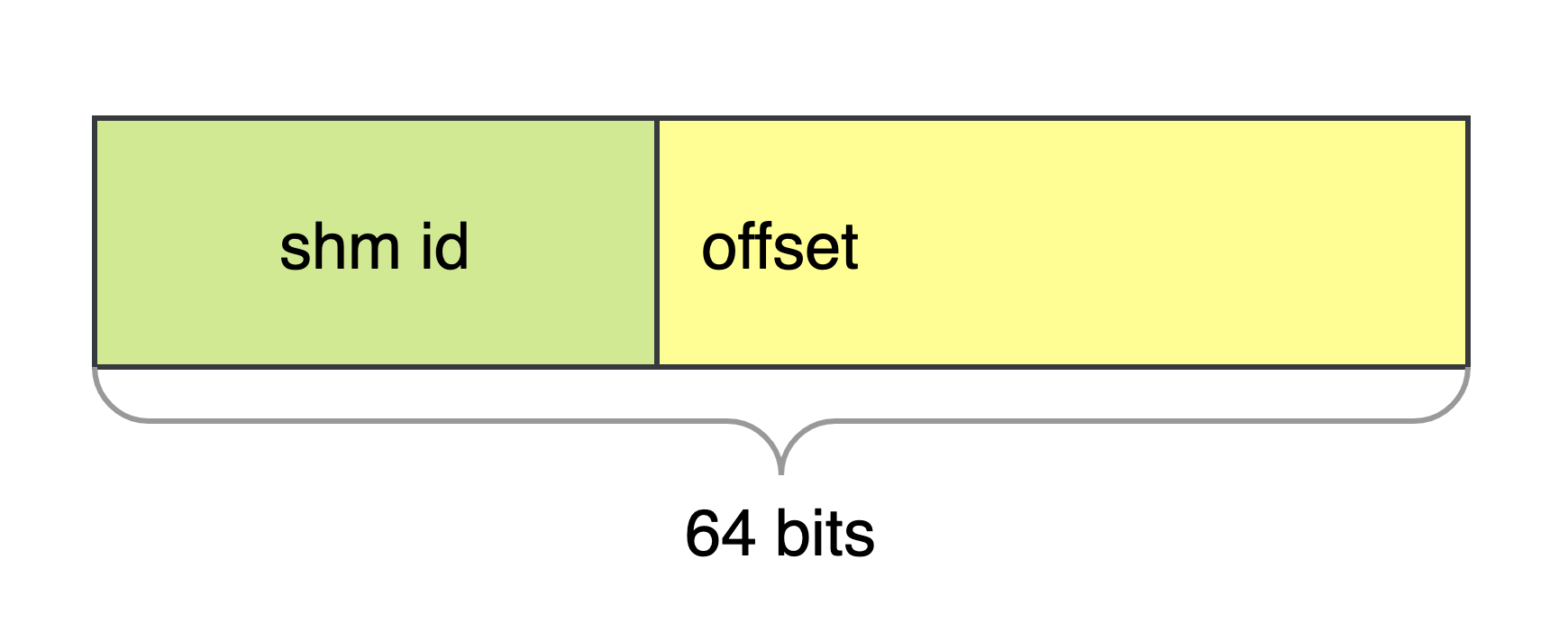
以 64 位地址为例,offset 只需占据 40 位就可以支持 1T 大小的单块共享内存,以目前的硬件内存价格来说,已经是相当充足了,剩下 24 位作为共享内存编号使用,支持管理 16M 个共享内存块,也相当富余。理论上说,“共享指针” 的这两部分构成比例,决定了管理较少但更大的共享内存块,或者更小但更多共享内存块。
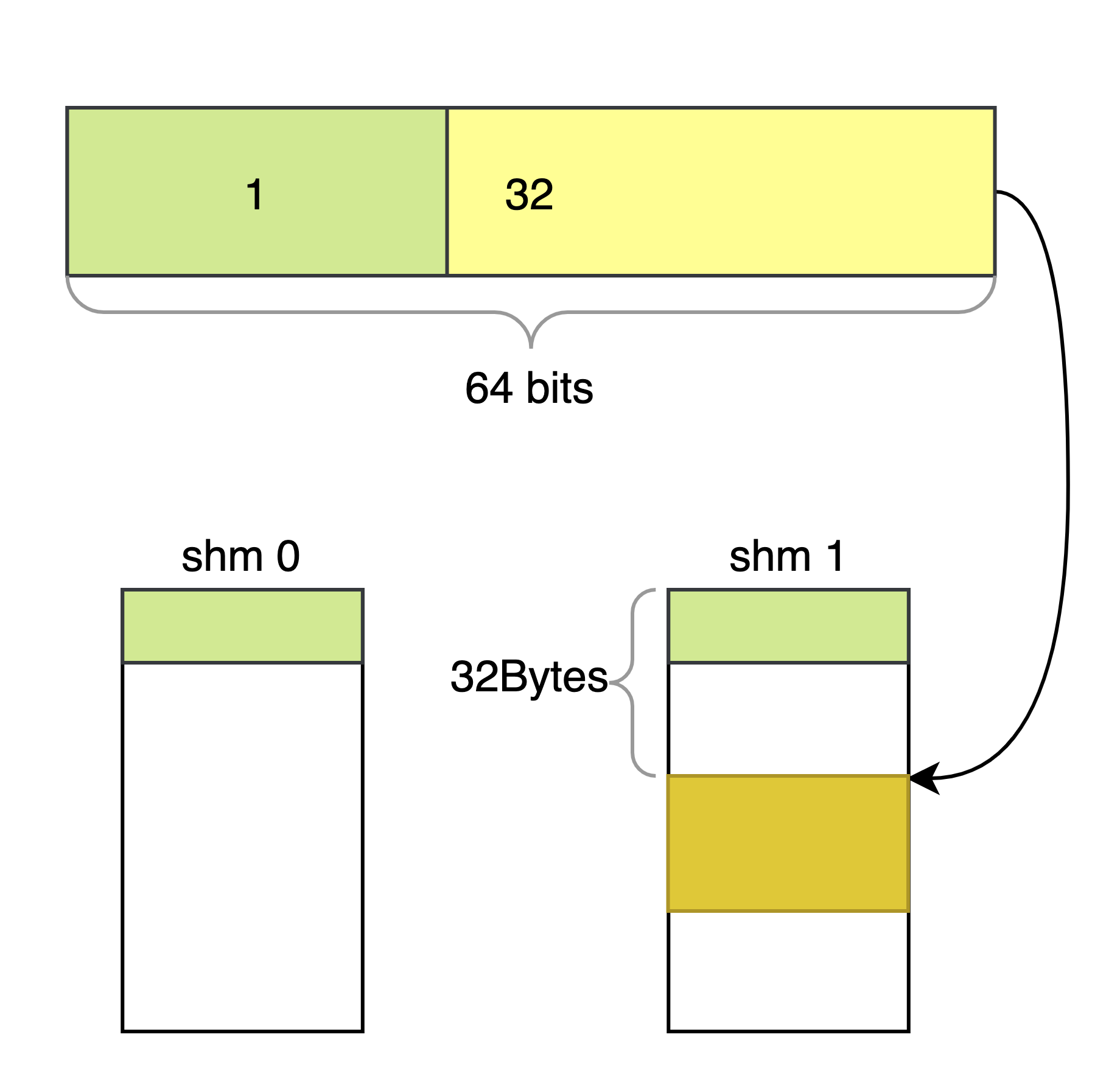
比如一个 “共享指针” 如图,它指向位于 1 号共享内存起始位置之后 32Bytes 位置的一块区域。共享内存中记录这些 “共享指针”,像一般指针一样构建复杂的结构。所有进程只需将 “共享指针”转换为自己的虚拟内存地址,就可以正确访问。
总结
只要 shm 中全部使用 “共享指针”,就可以扫清多进程共享内存地址映射的不一致性障碍,以很小的代价移植常见的内存管理方案。
