推荐书籍

这是我从大量算法书籍中精心筛选出来的,它
- 重视算法原理的理解,
- 用生动的例子替代晦涩的公式证明,
- 绘图也非常有趣,
对非专业开发者十分友好。 我的算法教程,也是以《算法图解》 为蓝本展开。
获取渠道
除了购买纸质图书外,你还可以从微信读书搜索到,领用无限读书券非常划算。
准备开始
本节我们参考的是《算法图解》第 10 章。 KNN 是机器学习领域的入门算法之一,KNN 就是 K 个最临近(Nearest)邻居(Neighbors),原理非常简单,通过对数据所在空间内统计附近若干元素来解决分类问题。我们的老祖宗也用一句话表述了类似的算法:物以类聚,人以群分。
我们会使用 scikit-learn,你可以使用
pip install scikit-learn
安装。
鸢[yuān]尾花数据
鸢尾花分类问题,是 KNN 算法的一个非常经典的案例,scikit-learn 库中已经自带了标记好的鸢尾花数据,共 150 条,包含:萼片和花瓣的长、宽。
我们将这些数据打乱以后,按照比例 3:1 分为 2 组,一组作为训练数据,一组作为测试数据。训练数据的作用,是生成 KNN 模型。计算机辛勤的生成模型,总需要对生成的结果进行评估,确定模型的有效性,这时测试数据就派上用场了。将测试数据通过模型计算得到结果,再与这些数据本身的分类进行比较,就可以得到模型的准确率了。
特别需要注意一点,训练数据和测试数据都是打好标记的,也就是这些花的分类是由人类智能分类好的。我记得河南某乡村被称为所谓的 “人工智能村”,应该就是生产这种标记好的数据,并不是真的在搞 “人工智能”。
通过下面的语句,就可以导入 iris 数据集。
from sklearn.datasets import load_iris
iris_dataset = load_iris()
由于 Iris 数据集是有序数据,如果直接按照 3:1 的比例将这些数据分割为:
- 训练数据
- 测试数据
数据的分布都集中在特定的区域,分布不均匀,所以需要将数据打散后再分割,scikit-learn 已经提供了响应的工具:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'], random_state=0)
磨刀
数据算是准备差不多了,CNN 要求特征本身可以作为分类的条件,模型才能真正发挥作用,比如橙子和苹果的颜色,就可以作为一个分类的条件,但是二者的价格就不一定了。在实际情况下也需要先观察数据。
import pandas as pd
import mglearn
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
# 按y_train着色
grr = pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o',
hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3)
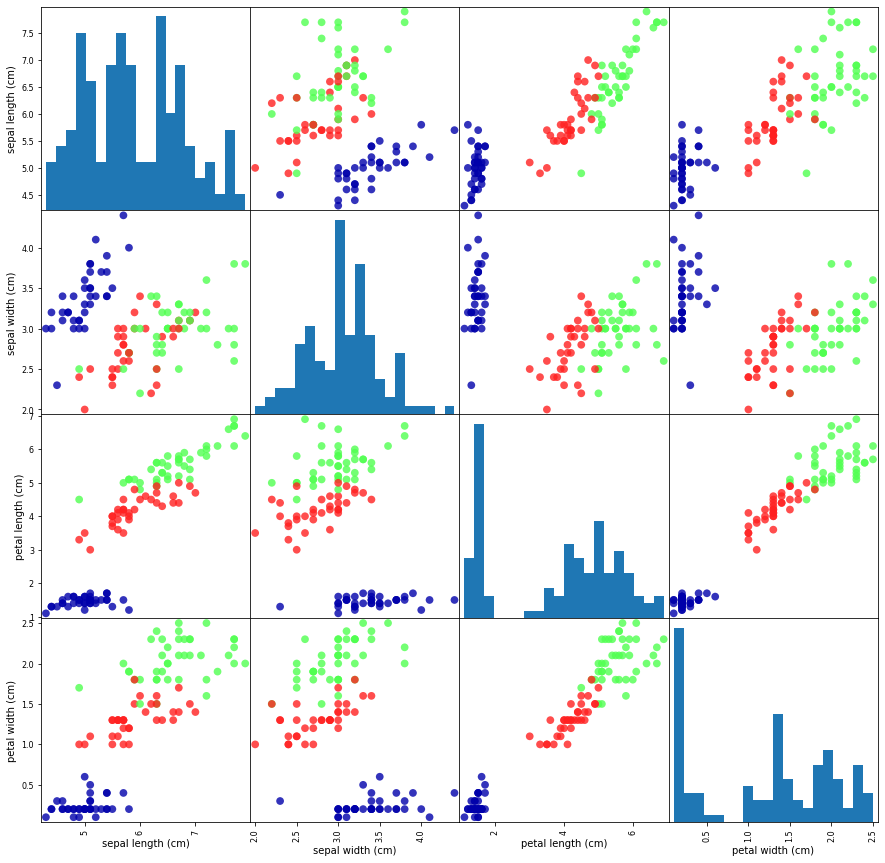
可以很清晰的看到,现有数据基本上可以将 3 种花分类,那我们就可以安心的继续下一步了。
砍柴
我们已经确定现有的数据可以用来产生分类器,下面就该构建一个模型了。感谢 Python 社区,我们无需从头生成一个模型,scikit-learn 已经提供了一些可用的分类器,就包括 KNN 分类器。我们需要做的只有:
- 初始化分类器参数(其实只有少量参数需要指定,其余参数保持默认即可),
- 训练模型,
- 评估、预测。
KNN 算法的 K 是指几个最近邻居,可以是1、2、3 或者更多,这里我们构建一个 K = 3 的模型。并且将训练数据 X_train 和 Y_train 作为参数,构建模型。
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
注意 knn 是个对象,fit 函数实际上修改的是 knn 对象的内部数据。现在 KNN 分类器已经就绪了。
使用 knn.predict 方法可以对数据进行预测,为了评估分类器的准确度,我们可以将预测结果与测试数据对比,计算命中率。
y_pred = knn.predict(X_test)
print("Test set predictions:\n {}".format(y_pred))
print("Test set score: {:.2f}".format(np.mean(y_pred == y_test)))

最后可以看到准确率可以达到 97%,还不错。你的结果应该也差不多。
从 KNN 到 机器学习
KNN 算法是一种:
- 理论非常简单,
- 训练快速(实际上基本不学习),
- 准确度较高,
同时:
- 计算量较大(计算样本与邻近点的距离)。
- KNN 模型依赖训练数据本身作为参数,内存消耗较大。
- 样本不平衡的时候,稀有类别预测准确率较低。
- 可解释性差,很难形成明确的规则。
虽然 KNN 非常简单粗暴,相比时下流行的深度学习还是有很大差别。但是其对数据的处理,学习,预测等过程,虽然简单,也具备了机器学习的基本要素。
代码在这里: https://github.com/JiangChuanGo/examples/blob/master/KNN/Iris.py
