上一节大致搞清楚了 Dict Object 的结构, 相比 《源码剖析》中陈儒先生研究的 2.5 版本,最新的 3.8 版本字典结构稍显复杂。不过,无论 Dict 的结构如何变化,其核心逻辑没有发生本质变化。今天剖析 Dict 的工作原理,哈希是如何在 Dict 中发挥作用的,碰撞问题如何解决?Dict key entries 的作用等等,这些问题很快都会得到解答。
创建 Dict Object
首先,还是回到 Dict 的结构,但是我会忽略掉那些暂时不打算关注的信息,只在需要的时候才会提到这些被忽略的信息,那么 Dict 可以简化为这样:
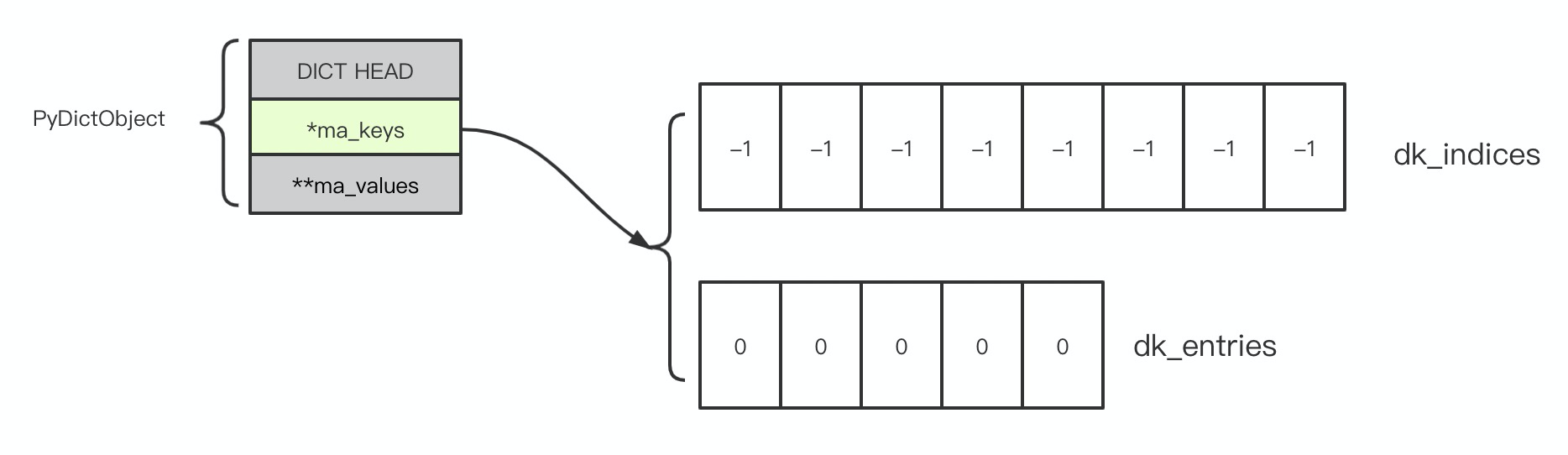
这样可以将注意力集中在 dk_indices 和 dk_entries 两个 C 数组上,为什么呢?因为:
- dk_indices 就是 key 的哈希表;
- dk_entries 是 key 数组。
Dict 的所有增查改删都发生在这里,当然,如果 Dict 处于 splited 状态,value 可能需要去 ma_values 里去找。图中所绘制的数组长度,是它们两个真实的初始值,分别为:
- dk_indices 初始大小 8;
- dk_entries 初始大小 5,这个 5 是根据 sizeof(dk_indices) * 2/3 计算出来的。
这里 dk_indices 的初始大小 8、dk_entries 是 dk_indices 大小的 2/3 都是一个经验值,前面提到过哈希函数的碰撞是不可避免的,实践证明这两个参数下,可以获得更好的碰撞性能。图中也标明了二者的初始值:
- dk_indices 全部为 -1;
- dk_entries 全部为 0, 一片空白。
Dcit Object 其实是通过 PyDict_New 创建的,但只要查看源码就会发现,新创建的 Dict 对象其实只是由一对全局 empty_keys 和 empty_value 组装起来的字典,本身并不能容纳数据。
// Objects/dictobject.c:698
PyObject *
PyDict_New(void)
{
dictkeys_incref(Py_EMPTY_KEYS);
return new_dict(Py_EMPTY_KEYS, empty_values);
}
Dict 真正转变为 “容器” 是在向其插入第一个元素的时候,其实现在下面的函数中:
// Objects/dictobject.c:1114
static int
insert_to_emptydict(PyDictObject *mp, PyObject *key, Py_hash_t hash,
PyObject *value)
{
// PyDict_MINSIZE 是 8;
// 创建初始大小的 keys,其中包含了长度为 8 的 dk_indices 和 长度为 5 的 dk_entries
PyDictKeysObject *newkeys = new_keys_object(PyDict_MINSIZE);
// 省略 ···
}
在 new_keys_object 中自动创建了 dk_indices 和 dk_entries,并且为它们赋予了合理的初始值。dk_entries 被全部清空为 0 是很合理的,dk_indices 则被设置为 0xFF 也就是 -1,这有特别的含义,意思是哈希表中这个位置 "空闲":
// Objects/dict-common.h:17
#define DKIX_EMPTY (-1)
#define DKIX_DUMMY (-2) /* Used internally */
#define DKIX_ERROR (-3)
另外还有一种状态 DUMMY,这在介绍字典的删除操作时再介绍,暂时让我们搁置它。
好了,现在我们知道,在 combined 模式(也是主要的一种状态下),dk_entries 就是 Dict 的 keys、values 栖身之所。而真正化 Dict 为神奇的,是 dk_indices。
解决哈希碰撞
虽然我们希望能有一种 “神奇” 的哈希函数,能够无碰撞的将所有 key 转换为一个整数 ix,此时将 key 保存在 dk_entries[ix],这样任何时候搜索 key 的问题就转换为线性数组的偏移访问,非常快。但理想是 C 杯,现实确比飞机场还骨感,对随机的 key,碰撞几乎不可避免。
Python 采用的技术称为 2 次探测,什么意思呢?当我们通过对象自身的 hash 函数将对象转换为一个整数 h,再经过另一个函数将 h 转换到 dk_indices 索引范围内的整数 i,如果 dk_indices[i] 已经被占用,那么就再计算一次转换,如果结果还是被占用,就继续尝试,直到找到空闲位置为止。
以一个简单的例子说明,尝试向一个 Empty Dict 插入 {9: "VALUE"},这里的 key 是整数 9,Python 中整数对象的 hash 就是其自身: 9。计算过程如下:
- 计算 9 % 8,实际上 Python 源码通过 9 &(8-1) 得到余数 1, 记为 i=1;
- 检查 dk_indices[1] == DKIX_EMPTY, 也就是 -1,该位置空闲;
- 将 dk_indices[1] 设置为 0, 0 是 dk_entries 的第一个位置,key 9 会被保存在这里;
- dk_entries[0].me_key 设置为 9(实际上是一个 LongObject)的引用;
- dk_entries[0].hash 设置为 9,因为整数的 hash 就是自身;
- dk_entries[0].me_value 设置为 "VALUE" (一个 StringObject )的引用;
此时 Dict 内部看起来这样:
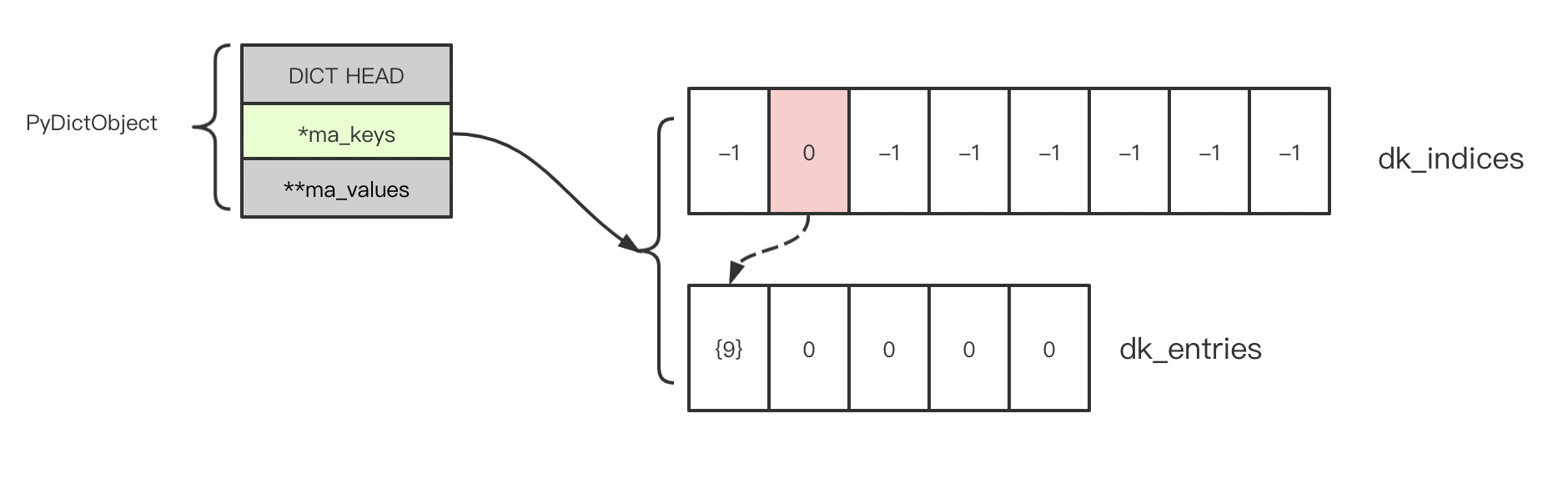
图中的数组都是 C 风格的,索引均从 0 开始计算。我已经将 dk_indices[1] 标记为红色,表示 “占用”。从 dk_indices[1] 中的值是 dk_entries 的索引 0,我用虚线表示它们之间的逻辑关联。
下面我们再构造一个碰撞,我们继续插入 {17: "APPLE"}
- 计算 17 % 8,余数依然为 1,记为 i=1;
- 检查 dk_indices[1],发现其为 0,不是负数,该位置被占用;
- 根据公式 ((5j) + 1) mod 2**i 计算下一个探测点, ((51) + 1) mod 2**i = 6;
- 检查 dk_indices[6], 空闲,设置为 1;
- dk_entries[1] 将用于保存新增加的值,dk_entries[0].me_key 设置为 17 的引用;
- dk_entries[1].hash 设置为 17;
- dk_entries[1].me_value 设置为 "APPLE" 的引用;
此时 Dict 看起来这样:
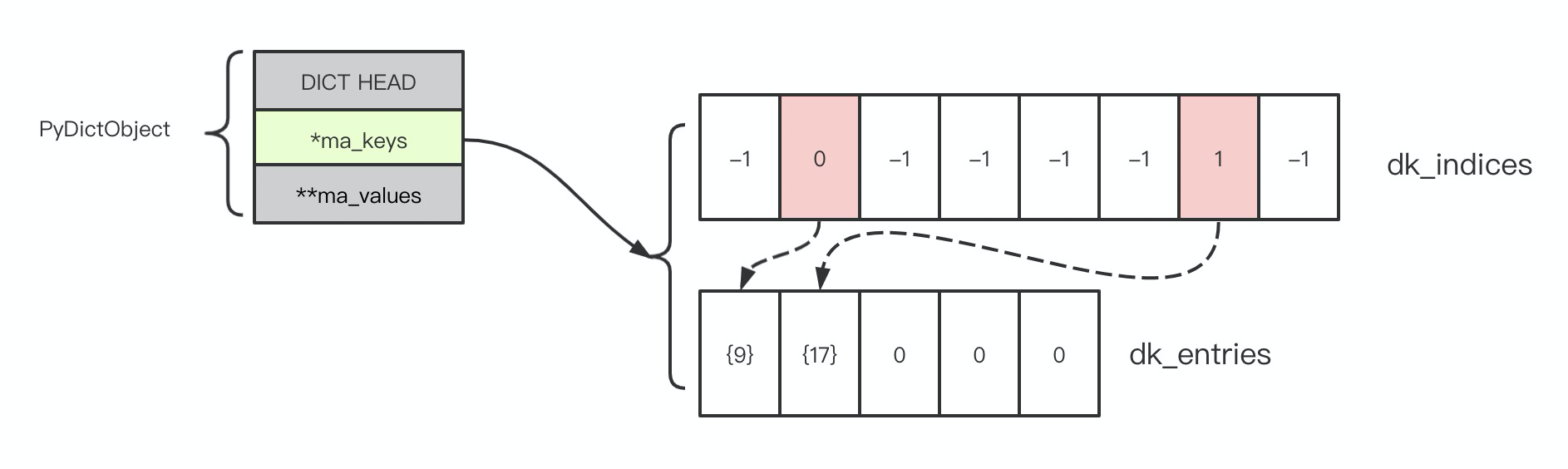
可以看到哈希表 dk_indices 中已经占用了 2 个位置,实际上这两个位置是碰撞的,但是通过两次探测,它们被均匀的分散开,这样就解决了哈希碰撞的问题。如果继续添加碰撞的 key,类似的过程会不断重复。对了,Dict 能装载的元素数量大约是哈希表的 2/3,这样是为了获得最好的哈希性能,如果需要更大的容量,当然会面临扩容问题,后面再研究。
注意到碰撞发生时采用了一个公式:
((5*j) + 1) mod 2**i
它有一些非常有用的特性,它可以保证经过 2**i 次探测,可以均匀的覆盖整个哈希表,比如第一次探测的位置是 0,哈希表的大小是 8,那么其后的探测链:
0 -> 1 -> 6 -> 7 -> 4 -> 5 -> 2 -> 3 -> 0
实际 Python 使用的探测函数与这里有一个很小的差别,为了避免相同余数的哈希全部碰撞到一起,会不断将 key 哈希值的高位加入到探测参数中,以便获得更好的散列性能。
