前一节以一个非常简单的例子,了解想 Dict 插入 K-V 的过程,简而言之:
- dk_indices 作为哈希表实现快速查询 Key;
- dk_entries 是 K-V 真实的栖身之所,就是一个数组;
哈希表中可能出现碰撞,Python 采用二次探测方案解决,即一次探测发现碰撞,就再探测下一位置,直到找到 empty 状态的 dk_indices 元素。
在 Dict 中插入数据不是目的,Dict 的目的是快速查找 Key,然后对 Value 进行改、删操作,可以说 Dict 的查找操作是其他操作的前提,如果 Dict 无法做到快速解决 Key 的搜索问题,那么 Dict 就失去了意义。
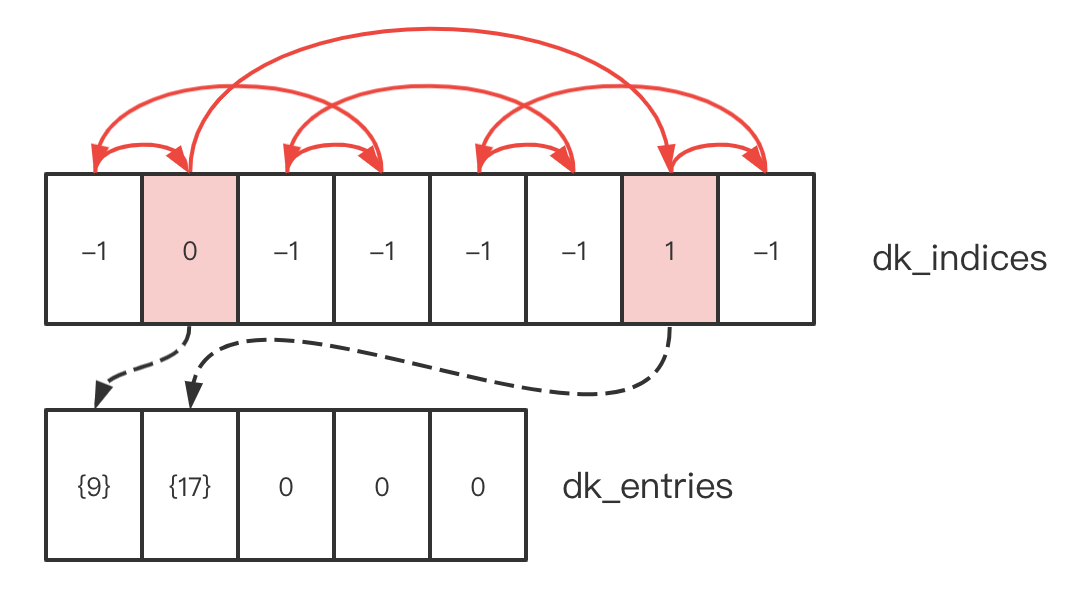
上图是 37 节对一个空字典插入两个 key 后 dk_indices 和 dk_entries 的样子,我用红色箭头标出了探测链,你可以从任意位置开始,找到其后每一跳的位置。这个探测链是根据之前提过的公式:
((5*j) + 1) mod 2**i
计算而来,对于大小为 8 的哈希表其结果是:
0 -> 1 -> 6 -> 7 -> 4 -> 5 -> 2 -> 3 -> 0
在 Dict 插入过程中,实际上也隐含了一个搜索过程,找到 Key 哈希探测链上第一个为 empty 的位置。那么在 Dict 中查找一个 Key 的步骤也类似,只不过条件转换为:
- 哈希表中找到一个不为 empty 的元素,并且该位置对应的 entry 与 Key 相等。
对于图中的字典 d,查找 d[9] 的步骤如下:
- 计算 9 % 8,得到余数 1, 记为 j=1;
- 检查 dk_indices[1], 该位置有非负的 “有效值”,记为 ix = 0;
- 检查 dk_entries[ix], 即 dk_entries[0],发现它的 me_key == 9, 找到 key;
由于 Key = 9 处于探测链条头部,第一次探测就找到目标,非常幸运。下面查找 d[17]:
- 计算 17 % 8,余数依然为 1,记为 j=1;
- 检查 dk_indices[1], 该位置有非负的 “有效值” 0,记为 ix = 0;
- 检查 dk_entries[ix], 即 dk_entries[0],其 me_key 为 9,不等于 17,所以这个位置是一个碰撞;
- 计算探测链下一跳位置,根据公式 ((5j) + 1) mod 2**i 计算, ((51) + 1) mod 2**i = j = 6;
- 检查 dk_indices[j], 即 dk_indices[6],该位置有非负的 “有效值” 1,记为 ix = 1;
- 检查 dk_entries[ix],发现其 me_key == 17,找到 key;
对于一个不存在的 key,最终会在哈希表 dk_indices 中找到一个 EMPTY 位置。
Dict 查找元素的基本思路是:
- 计算 Key 的 hash;
- 该 hash 与 哈希表 dk_indices 大小取模,找到第一个探测点;
- 如果该点的 Key 与目标 Key 相同,找到目标,退出;
- 如果该点为 EMPTY,说明已经到了探测链结尾,也没找到目标 Key,退出;
- 如果该点的 Key 与目标 Key 不同,那说明这是一个与目标 Key 哈希碰撞的 Key,则计算下一探测点,跳转到步骤 3。
事实上这里忽略一种情况,探测链中的某些元素可能被 “删除” 了,哈希表中对应位置的值是 DUMMY(-2),在 Dict 的删除一节我们会涉及,暂时不考虑这种情况。
