Set 是无序容器,它的插入顺序与迭代(或者 print)输出的顺序不保证与插入顺序一致,与 Dict 类似的问题,Set 的输出顺序是如何决定的呢?
首先我们从 Set 的输出开始寻找蛛丝马迹,在 Dict 的研究中,我们知道对象的输出由 *_repr 函数实现,对于 SetObject 这个函数是 set_repr:
// Objects/setobject.c:579
set_repr(PySetObject *so)
{
// ··· ···
// Set 转换为 List
keys = PySequence_List((PyObject *)so);
// ··· ···
// 获得 List 的字符串
listrepr = PyObject_Repr(keys);
// 截掉 List 输出左右两端的 "[" 和 "]"
tmp = PyUnicode_Substring(listrepr, 1, PyUnicode_GET_LENGTH(listrepr)-1);
// ··· ···
// 拼接输出
// ··· ···
return result;
}
Set 的输出经历了以下步骤:
- Set 转换为 List;
- List 转换为 String;
- 舍弃 List 输出左右两端的方括号,替换为小括号 ();
我们又一次见到了熟悉的面孔 PySequence_List,该函数的作用是将可迭代对象转换为 List 对象。Set 也是可迭代对象,具体的迭代操作由:
// Objects/setobject.c:867
static PyObject *setiter_iternext(setiterobject *si){
// ··· ···
}
该函数的代码表明 Set 对象的遍历,实际上是对 Set->table 的遍历,但是会忽略 NULL 和 dummy 元素。Set 的遍历顺序由其 table 中 entry 的实际排布决定。Set 元素的插入方式,可以参看上一节的介绍,其中包含了 Set 的 lookup 逻辑。
验证
下面以一个简单的例子验证我们的理解。首先创建一个空的 Set,命名为 a。为了方便,依然使用整数作为 Key,原因是整数的 hash 就是它们自身。
a = set()
此时 a 的 table 长度为初始值 8。依次插入 1~4,会分别插入 table[1~4]。当插入 5 的时候,5/8 > 3/5,table 会伸缩到 4 倍有效元素数量 5 * 4 = 20,在实际分配的时候,内存尺寸会对 2^n 向上取整, 实际伸缩 table 长度到 32。
a.update([1,2,3,4])
此时 table 的样子:
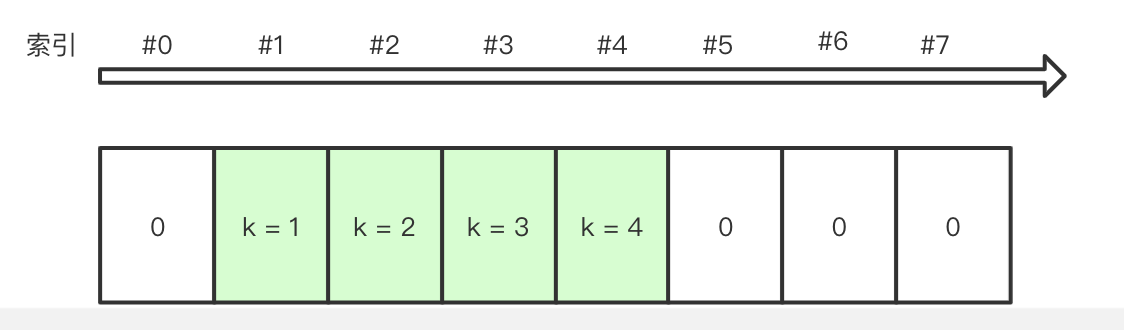
下面插入 5:
# resize the table firstly, then insert.
a.add(5)
经过 resize 的 table 看起来如此:
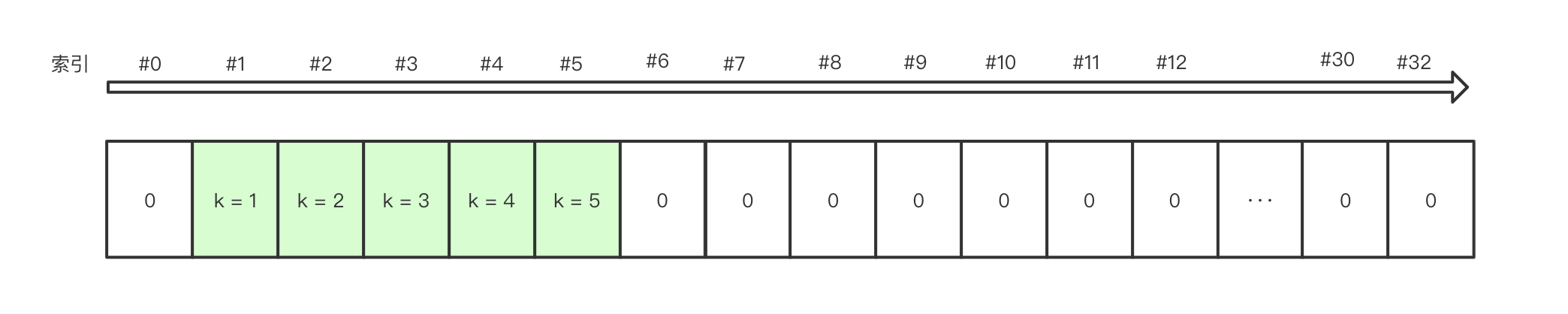
如果将 a 打印出来,输出的顺序应该就是 1~5,#0 处的 NULL 会被忽略掉。
print(a)
输出:
{1, 2, 3, 4, 5}
注意,此时 table 的长度已经是 32 了,下面插入一个较大的 Key = 32,对 32 求模刚好为 0,那么它会被插入到 #0:
a.add(32)
print(a)

上面的输出也可以印证这一点,输出:
{32, 1, 2, 3, 4, 5}
新插入的 32 打破了插入顺序和 Key 的大小顺序。 同理:
- 如果继续插入 Key = 39,它会出现在 #7 的位置;
- 再插入 Key = 70,则会出现在 #6 的位置;
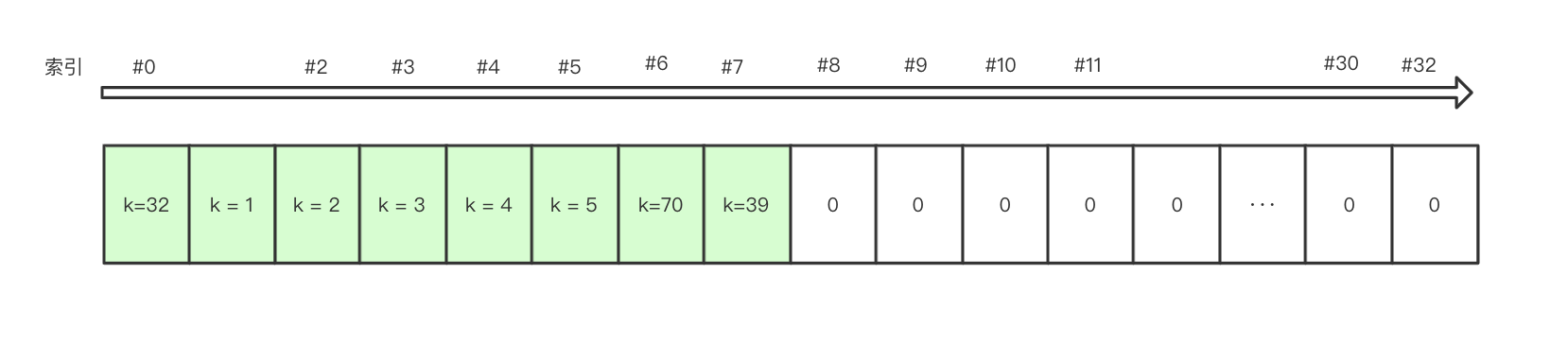
我们通过代码来验证
a.add(39)
a.add(70)
print(a)
输出:
{32, 1, 2, 3, 4, 5, 70, 39}
哈! 与预期完全一致!
