上一节我们说到,*.py 源码先后转换为 AST、ByteCode,最终到了 VM 这里付诸执行。有的朋友认为字节码的存在,是一种加速优化技术,某种程度上这样说是合理的,但这并不意味着 VM 可以同时支持 Python 源码和 ByteCode 两种输入。事实上,ByteCode 是 Python VM 唯一可以直接执行的文件,源码必须转换为 ByteCode 才能执行,ByteCode 自身的优化在于,对于相同的代码无需再次 “编译” 到 ByteCode。
反汇编
提到编译,如果有低级语言开发经验可能会立马联想到 C、C++ 之类编译型语言,从源码编译出可执行文件的流程。
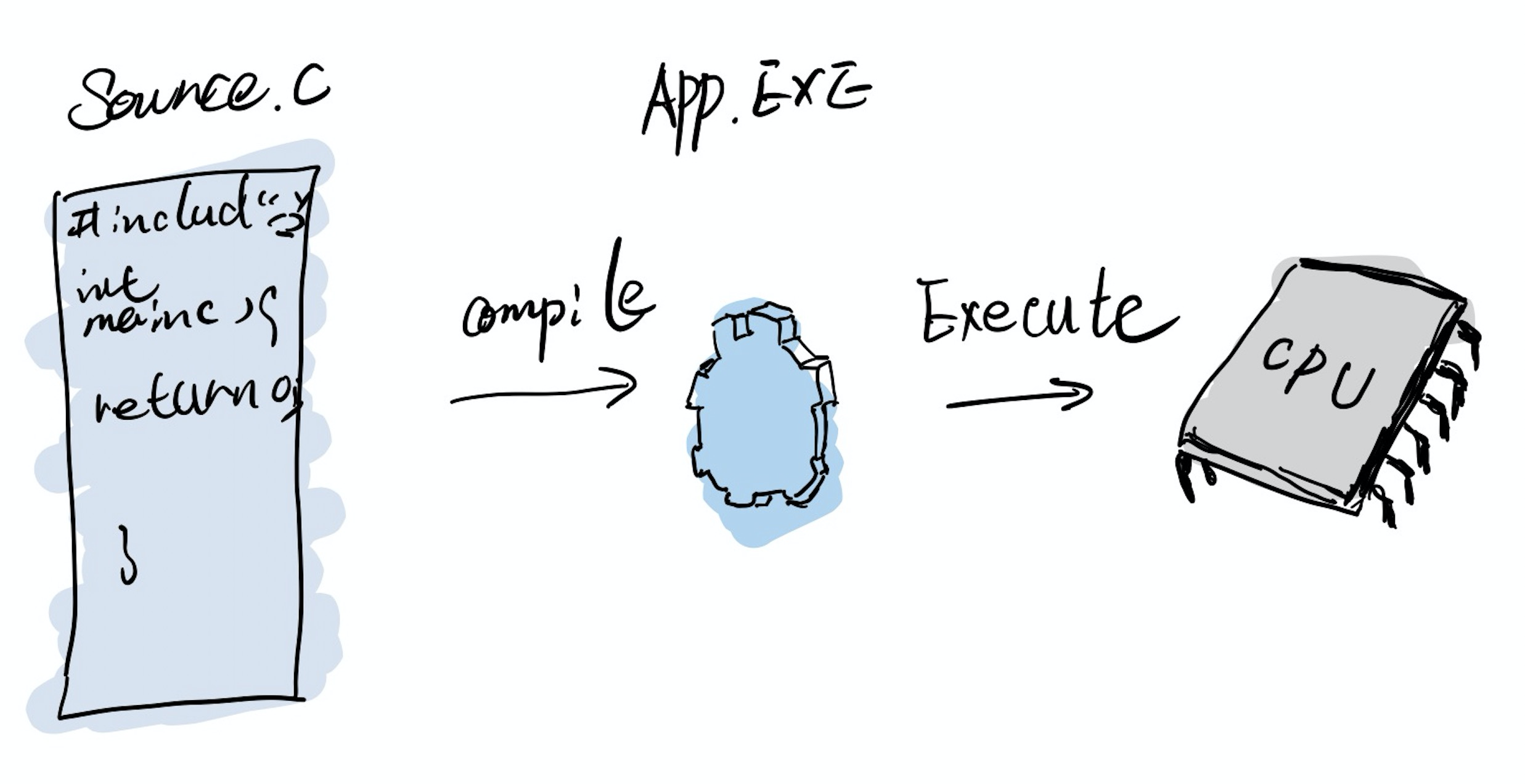
源码经过编译、链接之后得到可执行文件,最终由 CPU 直接运行。
Python 不是解释型语言吗,怎么也需要编译呢?其实编译过程广泛存在于现代脚本语言中,语言的实现大多基于某种虚拟机(VM)。Python 的编译目标是字节码,一种仅被 Python VM 接受的指令,不同于 CPU 的指令集,而是一种更加抽象的形式。Java 也采用了类似的字节码形式,而且也有对应的 Java VM,这也是支持 Java 的
write once, run anywhere!
口号的关键技术。
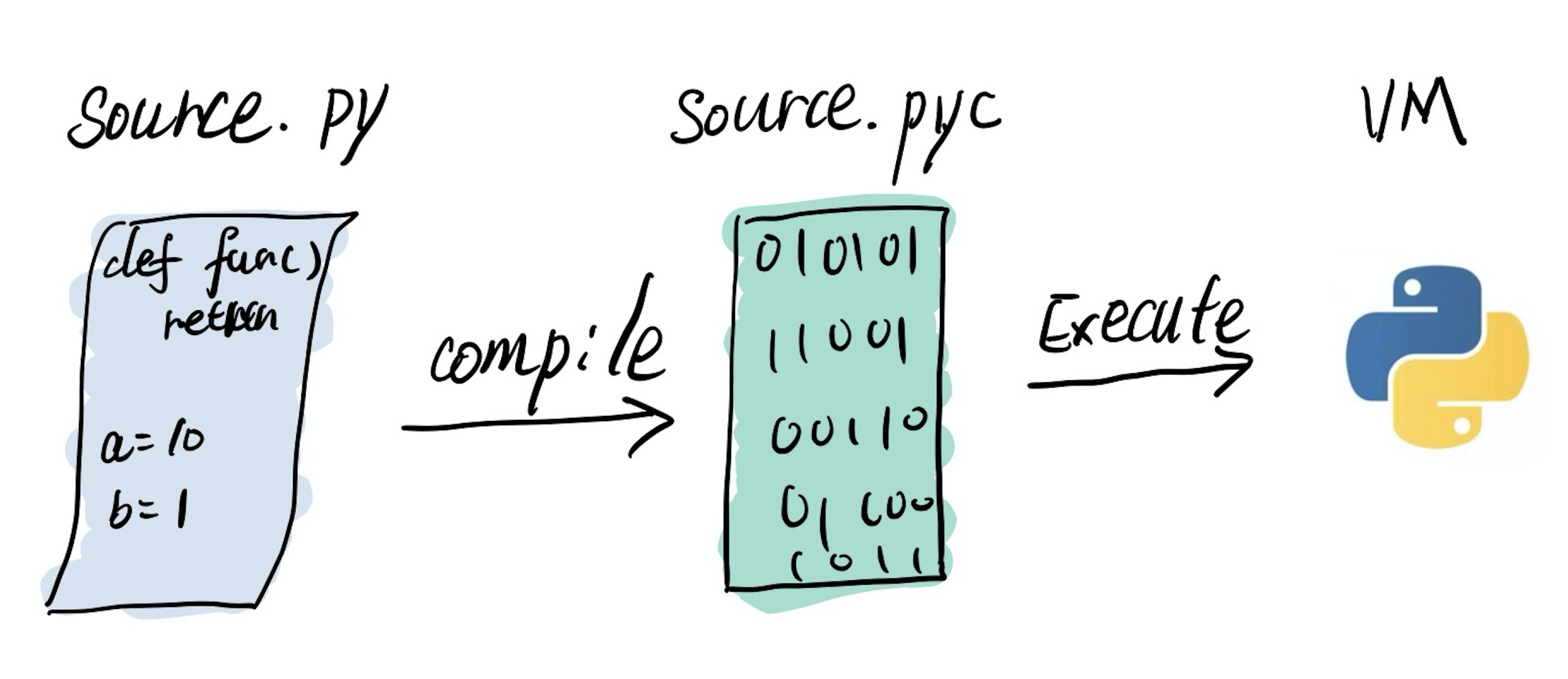
可以将 VM 看作一颗虚拟 CPU,Python 编译的结果也是一种可执行文件,只不过它只能由 Python VM 执行而已。
如此一来,很多低级语言中的技术也可以照搬到 Python 中。可执行文件都是只能由 CPU 识别的二进制代码,代码的组织也与源码相去甚远,很难直接阅读其含义。Python 的字节码也能被反汇编,得到一种更加易读的表示吗?
Python 中提供了 dis 模块,可以非常方便的对 Python 代码进行反汇编。VM 直接根据 ByteCode 的指令工作,那么这些指令也在相当程度上反映了 VM 的结构和工作原理,表里如一嘛!
闲话少叙,让我们看看 Python 的 “本质” 到底是个什么。
还是用最经典的 “hello world” 程序,并且对其 ByteCode 进行反汇编。
def fun():
print("hello world.")
import dis
print(dis.dis(fun))
上面的代码保存在 test.py, 用 python3 运行它,可以得到输出:
2 0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('hello world.')
4 CALL_FUNCTION 1
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
None
这就是 fun 函数的汇编(assembly)表示,比一大堆 0 和 1 看起来舒服的多了。VM 最终得到的指令大概就是这样了,根据指令的名称,可以大概看出它的执行逻辑:
- 加载全局变量 print;
- 加载常量 “hello world.”
- 调用函数;
- POP 栈顶元素;
- 加载常量 None;
- 函数返回。
这时你的大脑里应该可以想象出 VM 忙碌的样子,迅速的从全局变量中找到 print,再找到常量 “hello world.”,然后调用函数 ··· ···
执行过程
之后的 POP,看起来是不是很眼熟,是的,这是一个典型的栈(FILO)操作, Python 采用的是栈式虚拟机。VM 具体怎么工作的,暂时不必深究,下面绘制了 fun 工作时的过程。
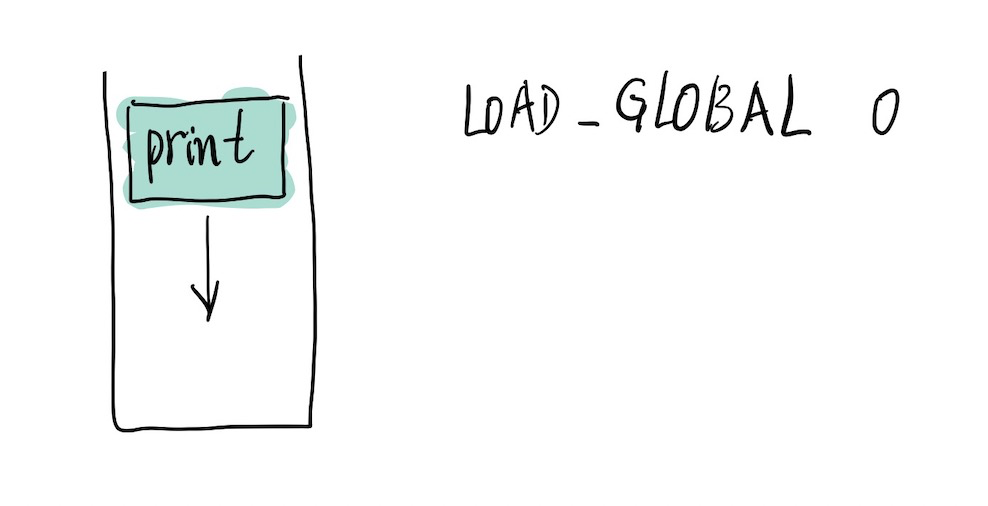
首先将 print 函数压入盏;
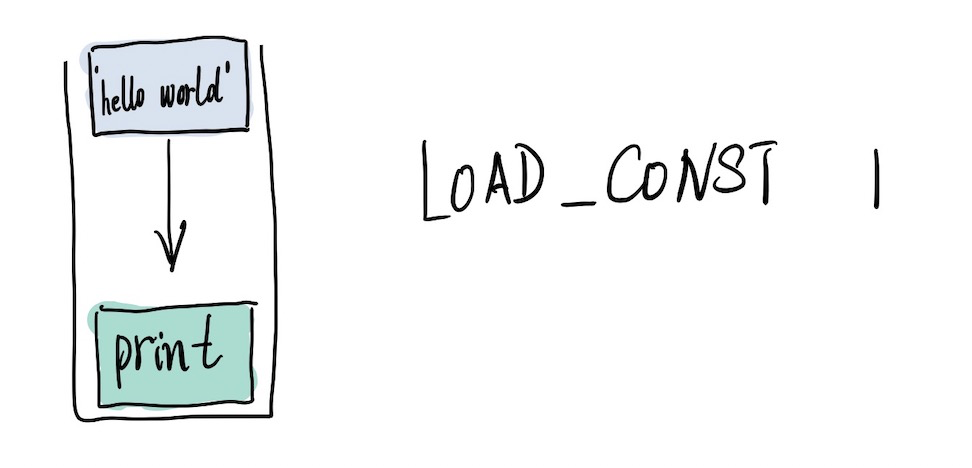
紧接着,压入字符串常量,显然它是 print 的一个参数;
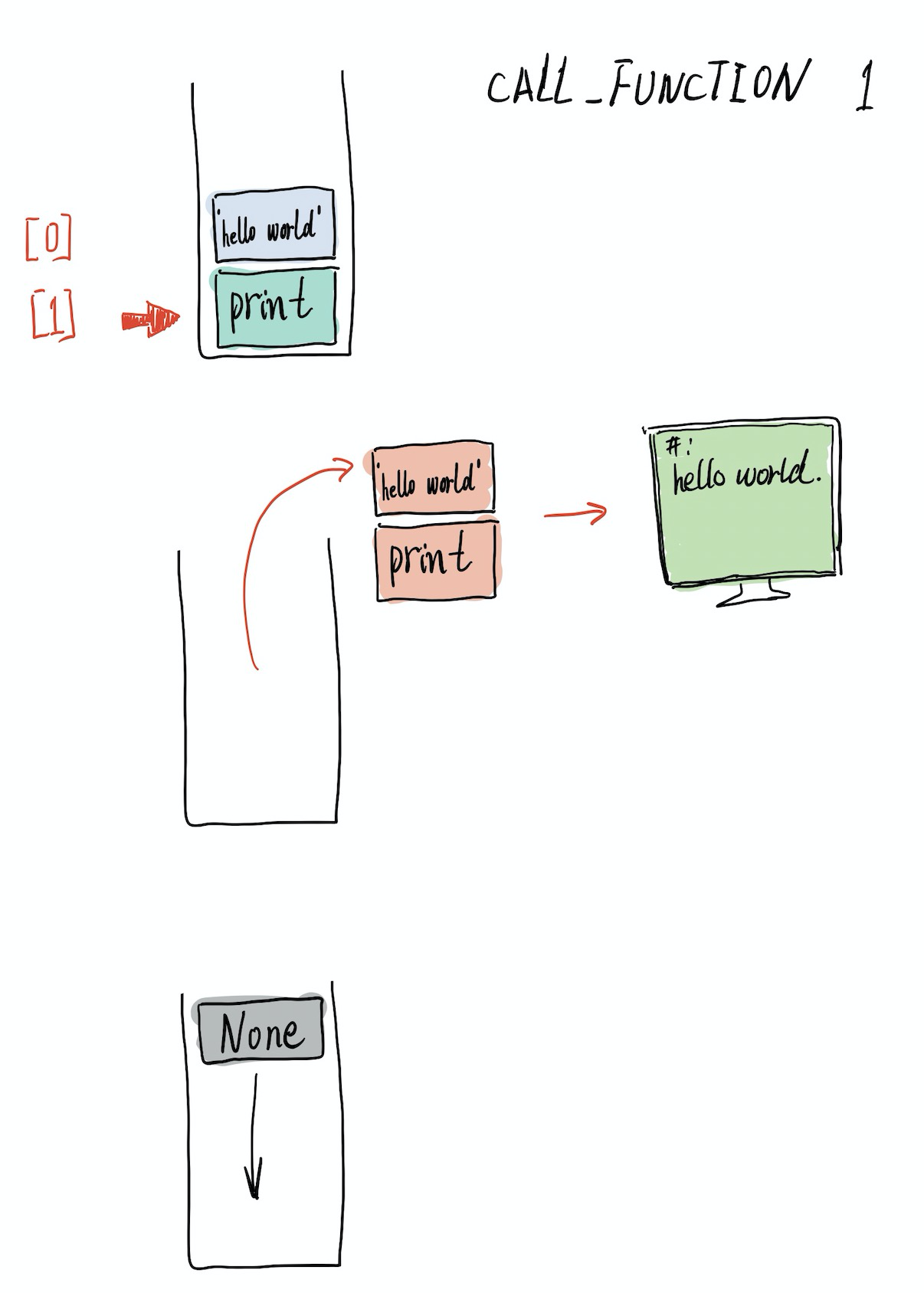
此时,从盏顶计算,stack[0] 是参数,stack[1] 是函数对象,CALL_FUNCTION 的参数 1 表明,需要调用 stack[1] 的函数。栈中所有元素被弹出执行,在屏幕上输出 “hello world.”,然后再将 print 函数的返回值压入栈。
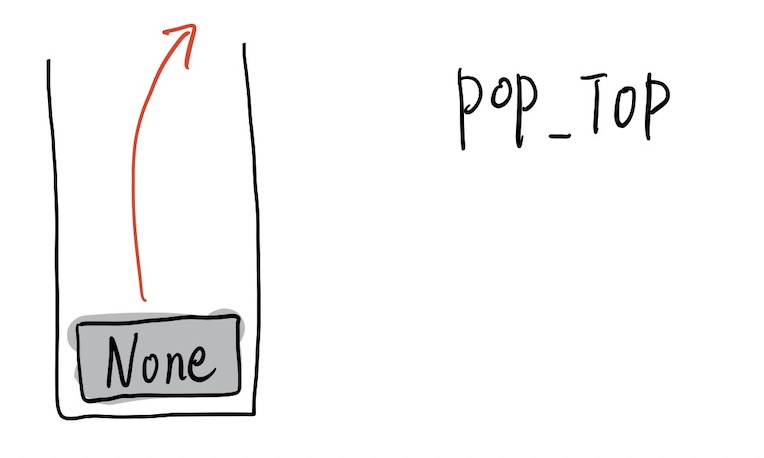
在 Python 源码中,print 函数的返回值被抛弃了,所以 print 函数的返回值被弹出栈,抛弃。
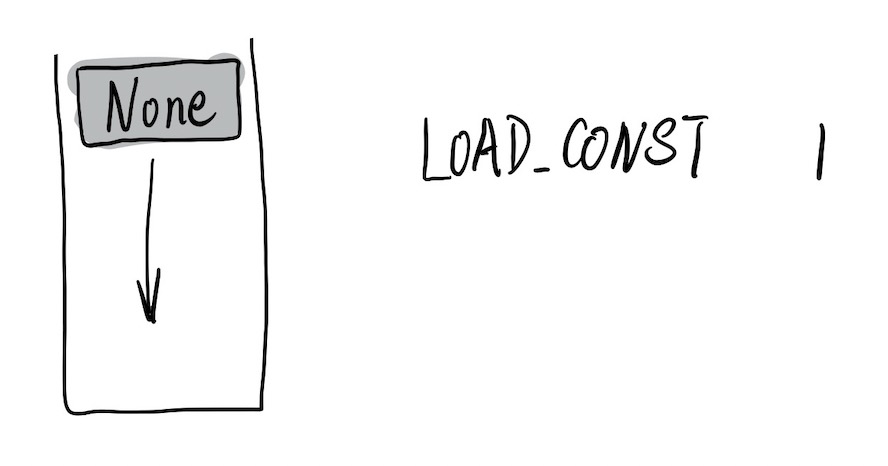
fun 函数没有定义返回值,所以它默认返回 None,需要将返回值 None 压入栈。
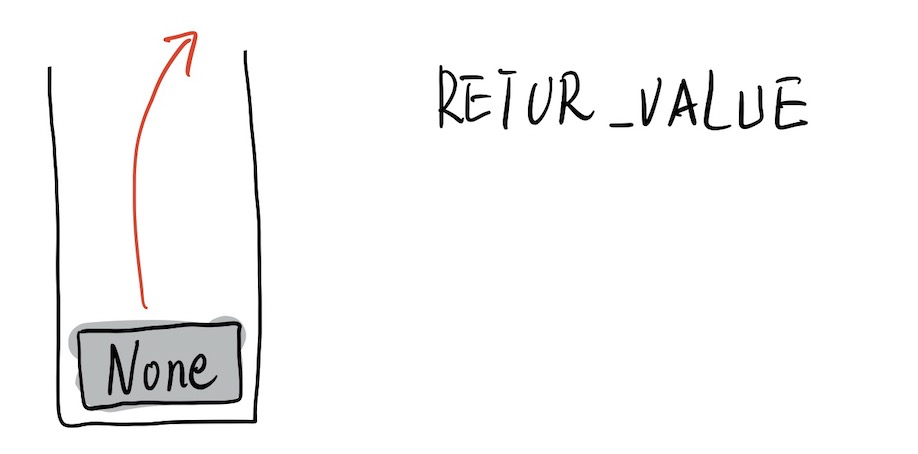
fun 运行的结尾,将返回值 None 弹出给调用者,fun 函数结束。
也许你认为最后 None 先出栈又入栈,完全没意义,确实,如果将中间过程删掉也没问题,但是这诚实的遵守了 Python 源码的用意。
