字节码 (ByteCode) 是一组精心构建的二进制表示,其中主要包含两种信息:
- 执行什么操作;
- 操作的参数;
除此之外 Python 中的各种常量、名称、变量也在字节码中。
Python 的面向对象非常彻底,字节码的管理也没有脱离对象,如同上一节提到的,VM 执行的是一个加 co 的东西,它的类型是 PyCodeObject,它是 ByteCode 的栖身之所。下面节选了其中最关键的部分:
/* Bytecode object */
typedef struct {
PyObject_HEAD
int co_argcount; /* 参数数量,不含可变参数 */
int co_posonlyargcount; /* 位置参数数量 */
int co_kwonlyargcount; /* 命名参数数量 */
int co_nlocals; /* 局部变量数量 */
int co_stacksize; /* 总的调用栈大小 */
int co_flags; /* 一些标识位 */
int co_firstlineno; /* 第一行代码的行号 */
PyObject *co_code; /* 字节码本尊! */
PyObject *co_consts; /* 常量,数组 */
PyObject *co_names; /* 名称,数组 */
PyObject *co_varnames; /* 局部变量名,元组*/
PyObject *co_freevars; /* 闭包中的变量,元组 */
PyObject *co_cellvars; /* 嵌套函数中的局部变量,元组 */
// ··· ···
} PyCodeObject;
后面还有一些成员这里没有列出,暂时不必关心他们。Python VM 总是会收到这样的 co 对象,当它收到这个对象就知道:
- 有多少参数;
- 用到了哪些局部变量;
- 需要准备多大的栈空间;
- 第一行有效代码是从何处开始的;
- 字节码和各种实际变量的情况;
这些信息都是在编译阶段生成的。
VM 就像得到了一份 CodeObject 的告白,娓娓道来,事无巨细。根据这些信息,VM 就可以做好执行 ByteCode 的准备,稳稳当当不会出什么纰漏。
这里第一行有效代码的行号信息,对生成调试信息很重要,已经可以看到原始的 py 文件,经过 “编译” 以后,已经面目全非了,如果不保存哪几行 ByteCode 是由哪一行 py 源码生成的,出了问题都不知道找谁去。在 co 中的 co_lnotab 的成员就完成了这样的工作,通常一行 py 源码可以生成多行 ByteCode,为了压缩数据,co_lnotab 记录的只是当前行相对上一行 py 源码的行号增量,这样一步一步就可以捋清除当前的真实行号。但第一行 py 源码是例外,因为它没有 “上一行”,就只好直接在 co 中保留一个属性记录这个信息了。
再贴出上一节反汇编出来的 ByteCode:
2 0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('hello world.')
4 CALL_FUNCTION 1
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
None
co 中所有的 CONST、NAME 之类的信息都单独保存在一个 list 中,而非直接嵌入汇编。这样的好处是,代码中多处使用的重复数据,只用保存一份就好了,比如多个地方用到 'hello world.',假设该字符串位于 CONST 列表的位置 0,那么只要指明加载 “CONST[0]” 就好了,无论代码里用到多少次 'hello world.',co 中都只存在一个副本,这样省了不少事儿!
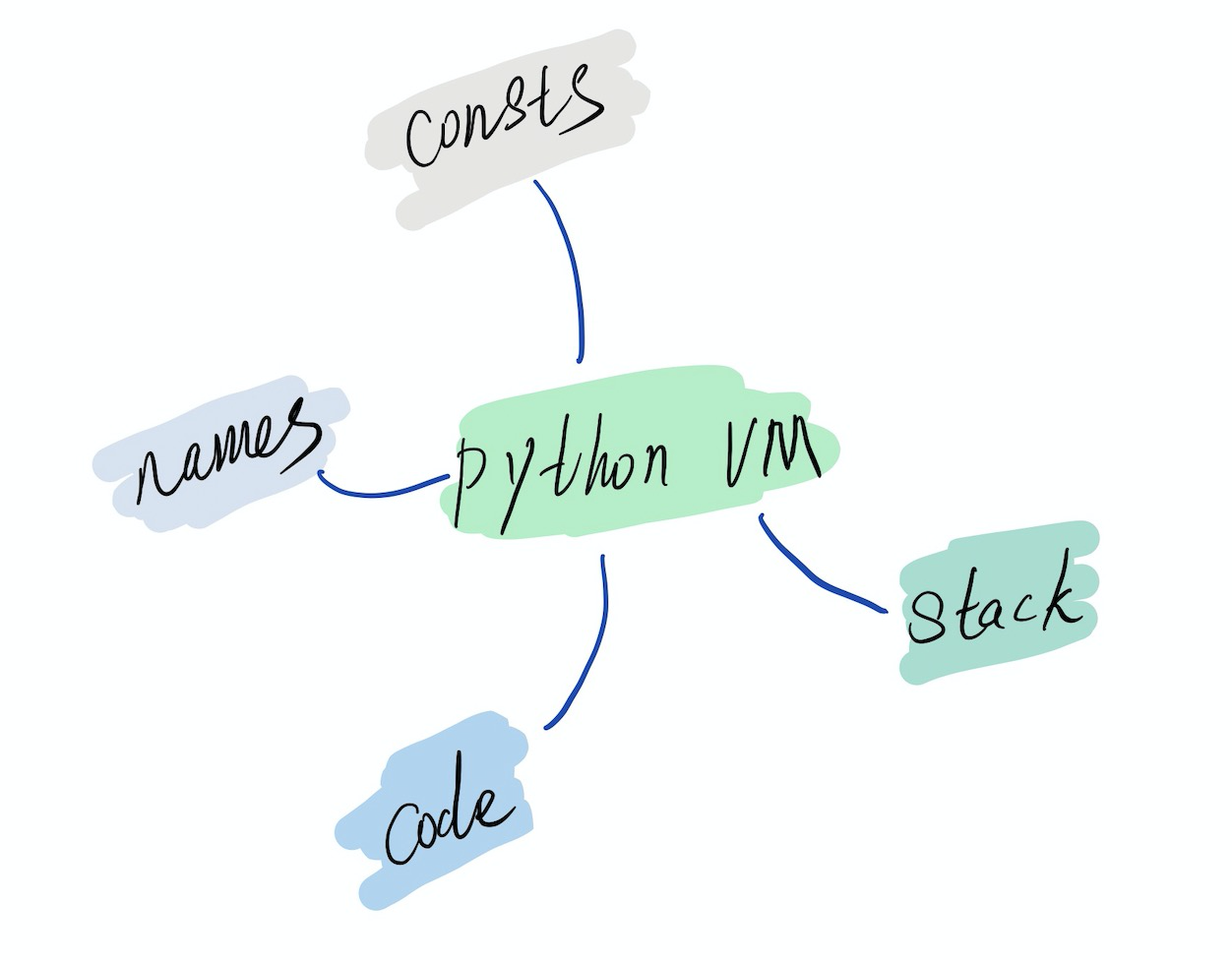
现在不妨让我们大胆的猜测 VM 中的图景:
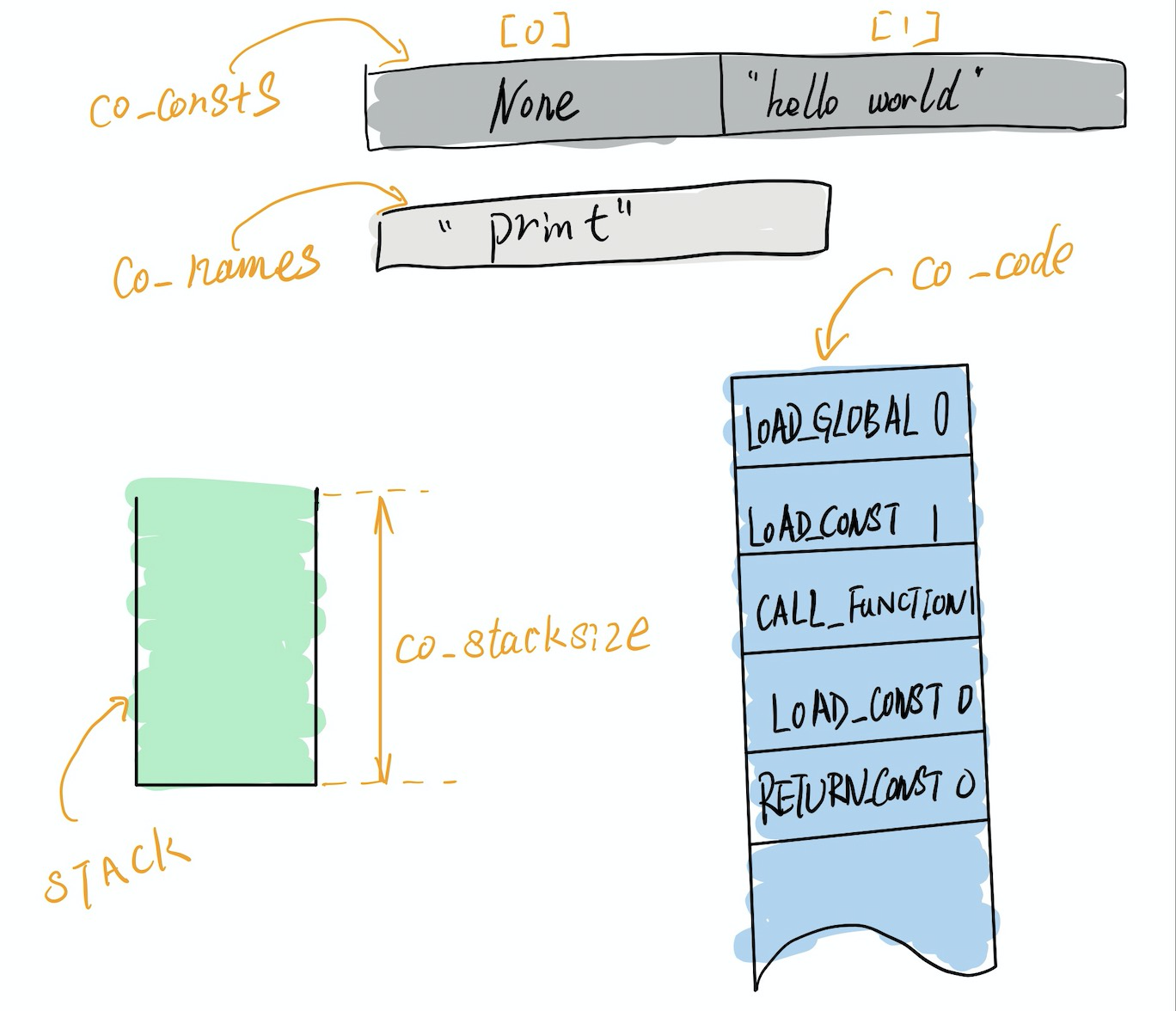
VM 通过解析 CodeObject,创建了这样一个执行环境,如果将 co_names 和 co_consts 都归结为常量,那么 VM 的执行环境可以总结为:
- 常量(不可变量、名称等等等)
- 变量(参数、局部变量等等)
- Code (真正的二进制字节码)
- 执行栈
所以通过 dis 模块反汇编得到的代码里,1 ('hello world.') 这样的东西并不是 ByteCode 中的真实情况,实际上 ByteCode 中的参数只有 1,括号里的信息是 dis 模块生成的辅助信息。
