最终 Python 的执行过程,实际上就是 Python VM 对 ByteCode 的解释过程。程序的三种基本结构:
- 顺序
- 条件
- 循环
数学上已经证明,这三种结构可以表述任意逻辑。Python 也不例外,ByteCode 中也必定实现了这三种结构。
顺序执行
顺序执行是最朴素的一种,CodeObject 就是 ByteCode 在 Frame 中的表示,我们可以通过反汇编对应的 pyc 文件,获得 “汇编代码”,在逻辑上这三种形式表达的是同一个逻辑。
CodeObject 的实现与 C 语言的 char [] 数组类似,一个个字节码顺序排开,Python VM 中通过一个超大的 while 循环,逐个读取这些指令,并一一执行。
以最简单的两行代码为例:
a = 1
b = 2
预先安装 xdis 模块后,使用可以先将代码编译为 pyc 文件,再反汇编得到汇编代码。那么字节码等效于下面:

刚好实践一下 65 节的内容。
正式的 Python 代码不太这么短,对应的字节码也会长的多,但它们没有本质的区别。
下面就需要 Python VM 出场了,首先 通过 1、2 指令,在局部变量字典中创建了 "a" -> 1 的关联,然后将读取的指针 + 1,读取下一条指令,创建 "b" -> 2 的关联。最后的加载的常量 None 和 RETURN_VALUE 指令是 Python 自动为 module 增加的返回值 None,希望你还记得 Python 将 py 文件处理为 module 这回事。
Python 通过不断将读取指针调整到相邻的下一个位置,自然的实现了顺序执行。
《源码解析》对这一部分展开较多,但在逻辑上反而简单的多。
条件执行
Python 中的条件语句主要通过 if 语句实现, 完整的 if 语句有以下几部分:
- 条件判断语句;
- True 时执行的指令;
- False 时执行的指令;
其中条件判断语句不再展开,它的结果只可能在运行栈中只会留下一个 boolean 或者与之等效的对象。
条件执行的 True 和 False 基本上可以认为是两个顺序执行的单元,当然这块可以嵌套其他更复杂的结构,我们暂时不考虑它们。转换成流程图是这样:
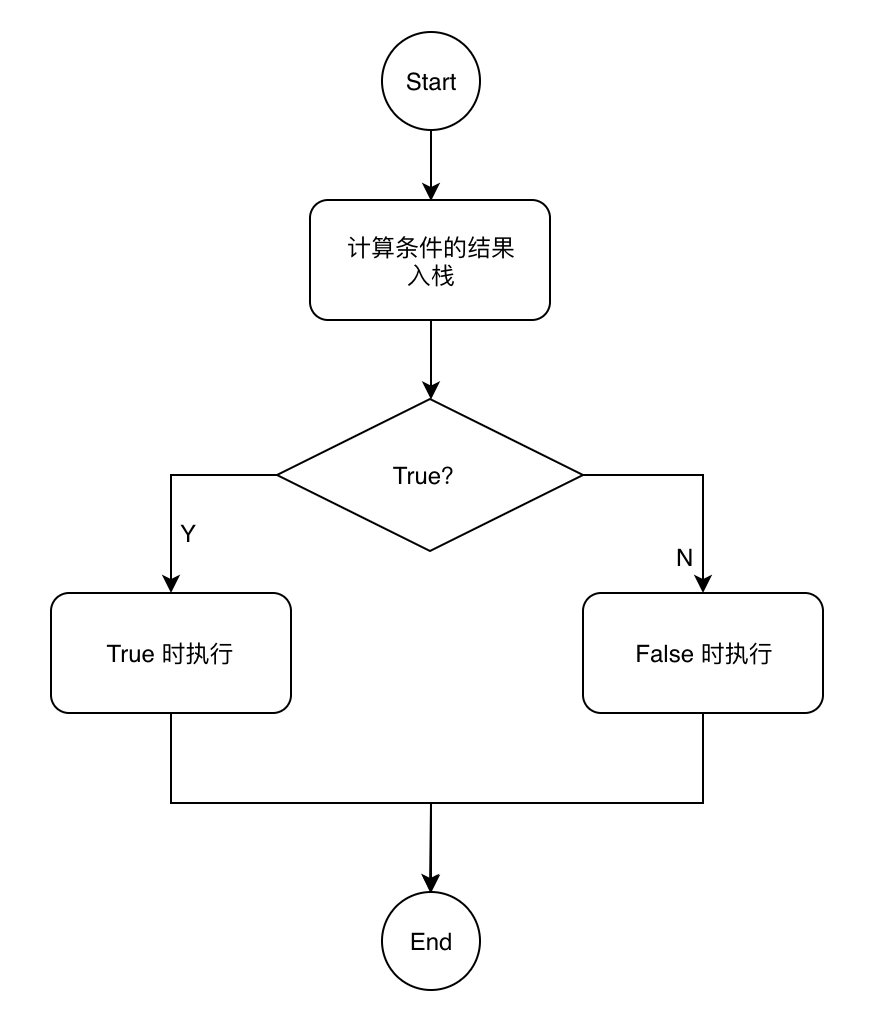
我们直到 ByteCode 实际上是一个连续的序列,不能像流程图中这样出现两个并列的代码块,我们来做一点位置调整,把它们挤压到一条线上:
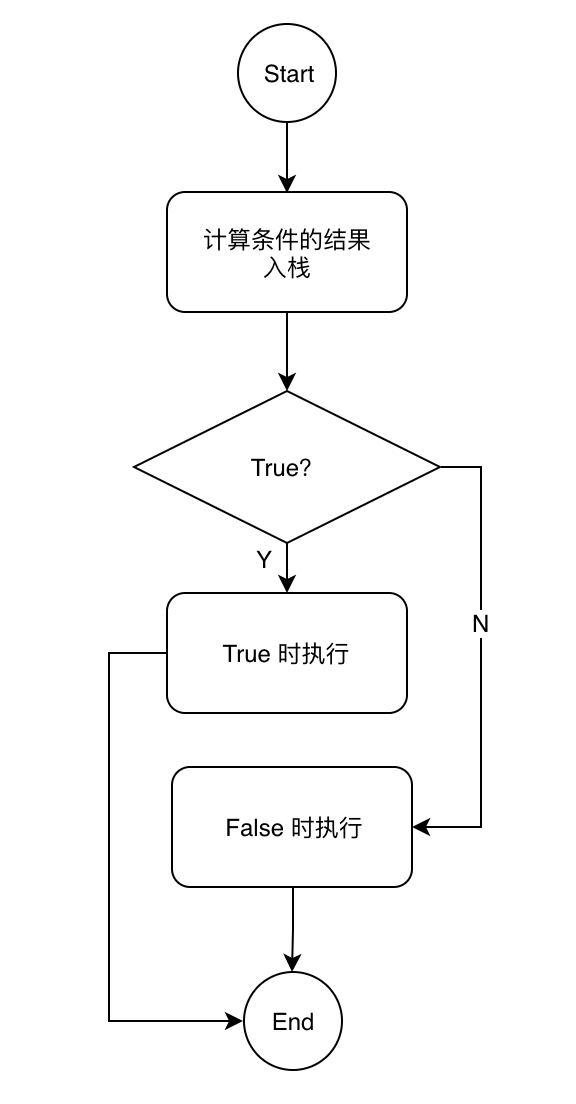
如果你仔细观察,上面的图实际上与最初的流程图是等效的,只是对位置稍作调整。
好,下面让我们看一下简单 if 语句是如何实现的:
if true:
a = 1
else:
a = 2
下面是与之对应的汇编代码:
# Constants:
# 0: 1
# 1: 2
# 2: None
# Names:
# 0: true
# 1: a
1: 0 LOAD_NAME (true)
2 POP_JUMP_IF_FALSE (to 10)
2: 4 LOAD_CONST (1)
6 STORE_NAME (a)
8 JUMP_FORWARD (to 14)
4: >> 10 LOAD_CONST (2)
12 STORE_NAME (a)
>> 14 LOAD_CONST (None)
16 RETURN_VALUE
注意:
- 0 加载待判断的 boolean 对象到运行栈,这里我直接指定为 True;
- 2 根据栈中(也就是上一步加载的对象),如果为 False 就跳转到标号 10,否则什么也做,继续下一指令;
- 4、6 实现了 a = 1;
- 8 跳转出 if 语句,这是一个无条件跳转,只要执行到 8 就一定会跳转到 14;
- 10、12 类似,实现了 a = 2;
- 14、16 已经在 if 语句之外,是 module 的返回值。
让我们把汇编的路径绘制出来:
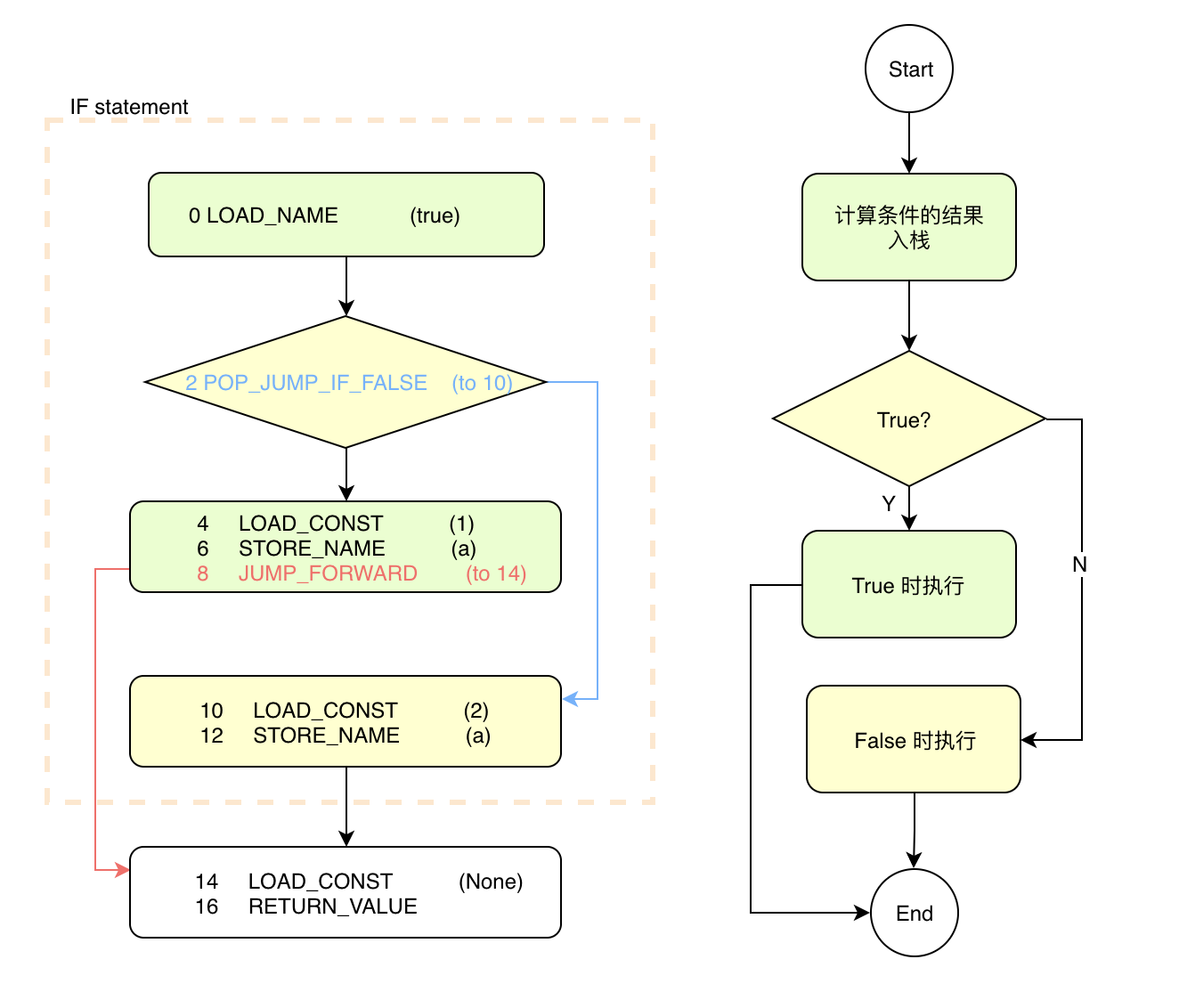
为了便于识别,我将汇编代码的路径和流程图放在一起,并且将:
- 对应单元间隔着色,
- 跳转路径与对应跳转语句着色。
我相信你可以一眼看出汇编代码是如何与流程图对应起来了!
总结
从字节码的角度看, Python VM 在相当大程度上可以认为是一个 “软 CPU”,基本预计的实现与硬件 CPU 的汇编如出一辙。今天一口气介绍了两种基本执行结构。下一步我们要了解循环的实现。
在 x86 等常见 CPU 架构下,循环是通过对 “条件跳转” 指令的精巧安排实现的,很少在 CPU 层面实现专门用于循环的机器指令,Python 作为一种高级抽象语言,它的特殊性在循环的实现上体现出来了,它采用了一种更抽象的实现方式。
让我们拭目以待!
